转载自编程小梦
What is Druid
Druid 是一个开源的实时 OLAP 系统,可以对超大规模数据提供亚秒级查询,其具有以下特点:
- 列式存储
- 倒排索引 (基于 Bitmap 实现)
- 分布式的 Shared-Nothing 架构 (高可用,易扩展是 Druid 的设计目标)
- 实时摄入 (数据被 Druid 实时摄入后便可以立即查询)
Why Druid
为了能够提取利用大数据的商业价值,我们必然需要对数据进行分析,尤其是多维分析, 但是在几年前,整个业界并没有一款很好的 OLAP 工具,各种多维分析的方式如下图所示:
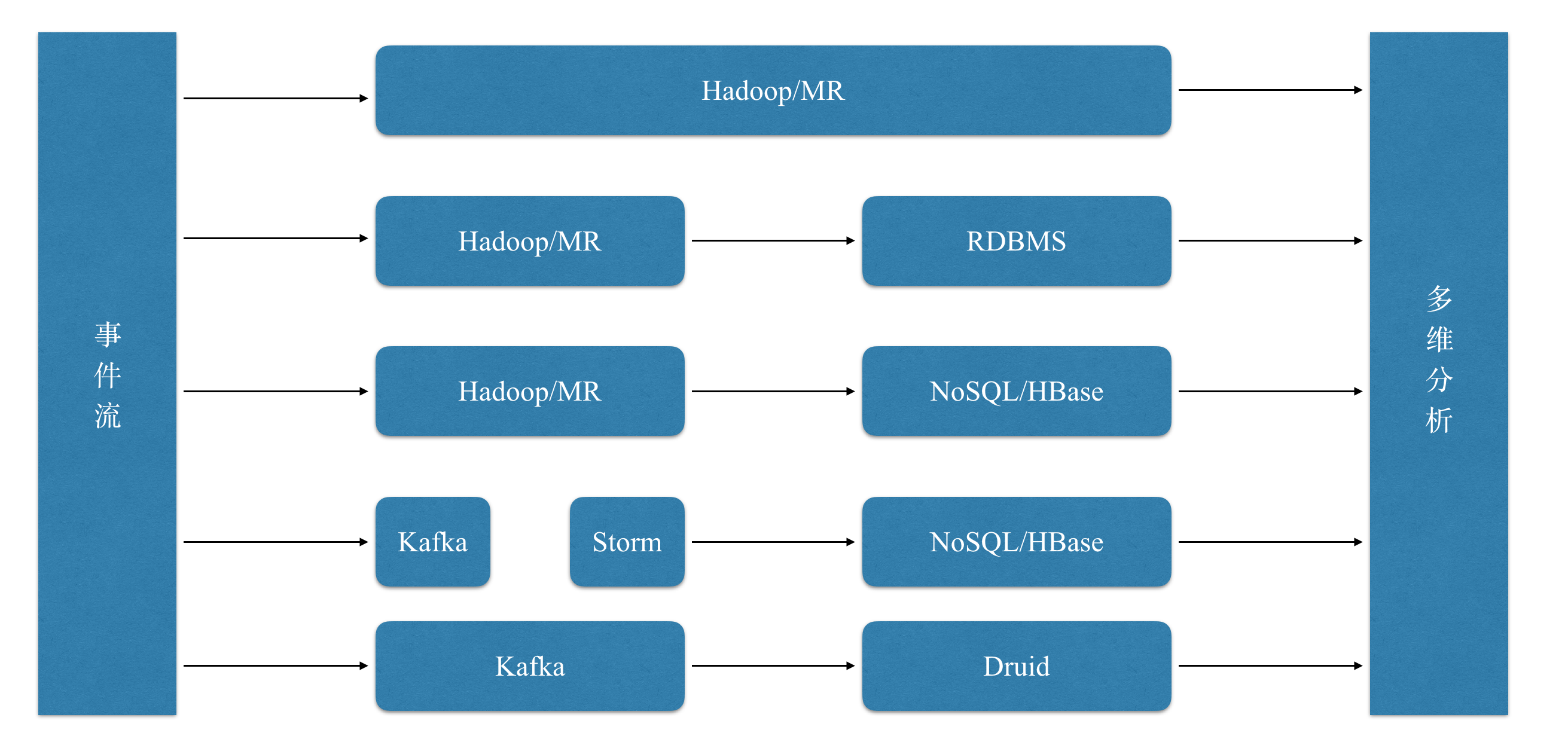
其中直接基于 Hive,MR,Spark 的方式查询速度一般十分慢,并发低;而传统的关系型数据库无法支撑大规模数据;以 HBase 为代表的 NoSQL 数据库也无法提供高效的过滤,聚合能力。正因为现有工具有着各种各样的痛点,Druid 应运而生,以下几点自然是其设计目标:
- 快速查询
- 可以支撑大规模数据集
- 高效的过滤和聚合
- 实时摄入
Druid 架构
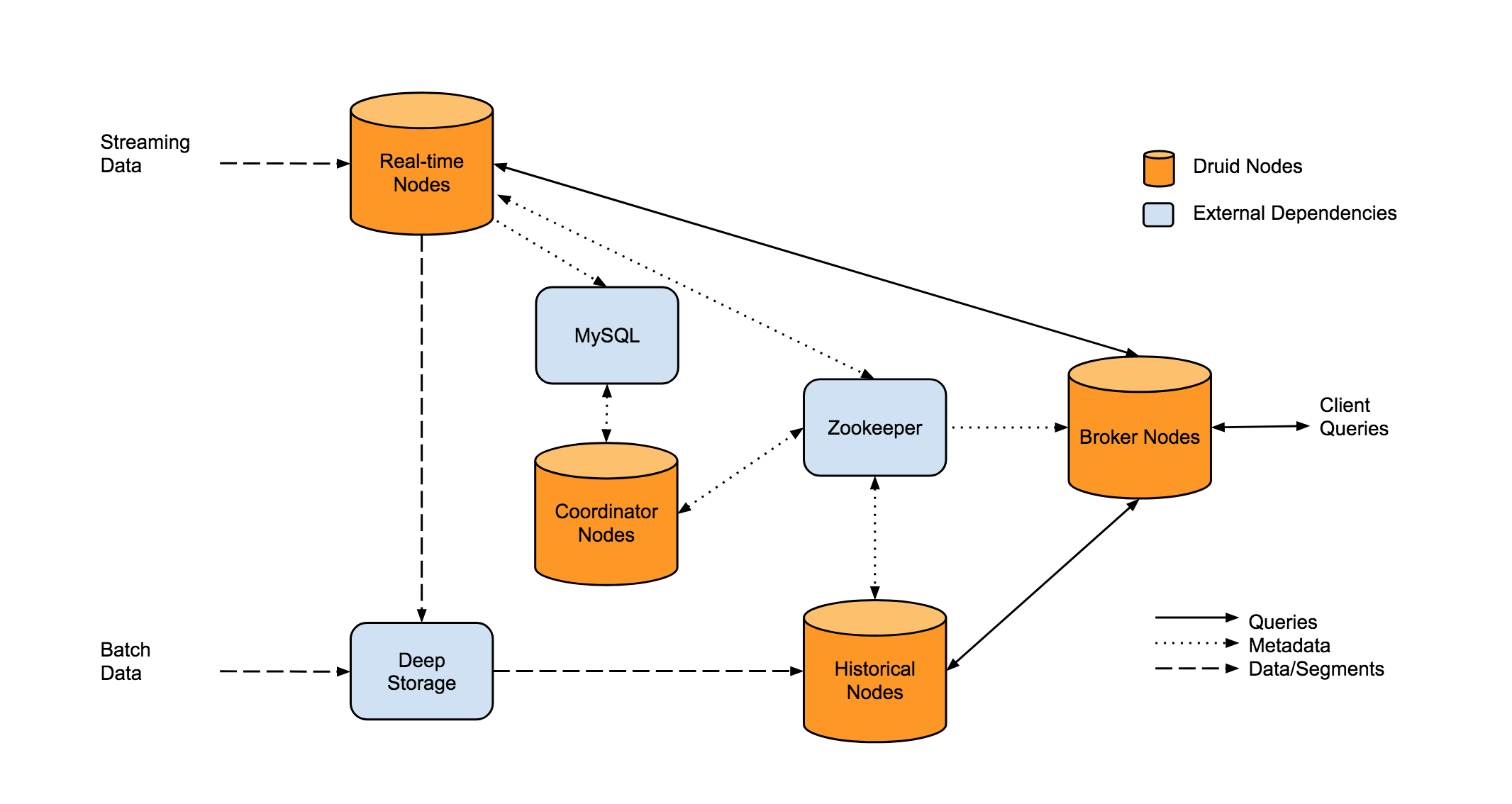
Druid 的整体架构如上图所示,其中主要有 3 条路线:
实时摄入的过程: 实时数据会首先按行摄入 Real-time Nodes,Real-time Nodes 会先将每行的数据加入到 1 个 map 中,等达到一定的行数或者大小限制时,Real-time Nodes 就会将内存中的 map 持久化到磁盘中,Real-time Nodes 会按照 segmentGranularity 将一定时间段内的小文件 merge 为一个大文件,生成 Segment,然后将 Segment 上传到 Deep Storage(HDFS,S3)中,Coordinator 知道有 Segment 生成后,会通知相应的 Historical Node 下载对应的 Segment,并负责该 Segment 的查询。
离线摄入的过程: 离线摄入的过程比较简单,就是直接通过 MR job 生成 Segment,剩下的逻辑和实时摄入相同:
用户查询过程: 用户的查询都是直接发送到 Broker Node,Broker Node 会将查询分发到 Real-time 节点和 Historical 节点,然后将结果合并后返回给用户。
各节点的主要职责如下:
Historical Nodes
Historical 节点是整个 Druid 集群的骨干,主要负责加载不可变的 segment,并负责 Segment 的查询(注意,Segment 必须加载到 Historical 的内存中才可以提供查询)。Historical 节点是无状态的,所以可以轻易的横向扩展和快速恢复。Historical 节点 load 和 un-load segment 是依赖 ZK 的,但是即使 ZK 挂掉,Historical 依然可以对已经加载的 Segment 提供查询,只是不能再 load 新 segment,drop 旧 segment。
Broker Nodes
Broker 节点是 Druid 查询的入口,主要负责查询的分发和 Merge。 之外,Broker 还会对不可变的 Segment 的查询结果进行 LRU 缓存。
Coordinator Nodes
Coordinator 节点主要负责 Segment 的管理。Coordinator 节点会通知 Historical 节点加载新 Segment,删除旧 Segment,复制 Segment,以及 Segment 间的复杂均衡。
Coordinator 节点依赖 ZK 确定 Historical 的存活和集群 Segment 的分布。
Real-time Node
实时节点主要负责数据的实时摄入,实时数据的查询,将实时数据转为 Segment,将 Segment Hand off 给 Historical 节点。
Zookeeper
Druid 依赖 ZK 实现服务发现,数据拓扑的感知,以及 Coordinator 的选主。
Metadata Storage
Metadata storage(Mysql) 主要用来存储 Segment 和配置的元数据。当有新 Segment 生成时,就会将 Segment 的元信息写入 metadata store, Coordinator 节点会监控 Metadata store 从而知道何时 load 新 Segment,何时 drop 旧 Segment。注意,查询时不会涉及 Metadata store。
Deep Storage
Deep storage (S3 and HDFS) 是作为 Segment 的永久备份,查询时同样不会涉及 Deep storage。
Column

Druid 中的列主要分为 3 类:时间列,维度列,指标列。Druid 在数据摄入和查询时都依赖时间列,这也是合理的,因为多维分析一般都带有时间维度。维度和指标是 OLAP 系统中常见的概念,维度主要是事件的属性,在查询时一般用来 filtering 和 group by,指标是用来聚合和计算的,一般是数值类型,像 count,sum,min,max 等。
Druid 中的维度列支持 String,Long,Float,不过只有 String 类型支持倒排索引;指标列支持 Long,Float,Complex, 其中 Complex 指标包含 HyperUnique,Cardinality,Histogram,Sketch 等复杂指标。强类型的好处是可以更好的对每 1 列进行编码和压缩, 也可以保证数据索引的高效性和查询性能。
Segment
前面提到过,Druid 中会按时间段生成不可变的带倒排索引的列式文件,这个文件就称之为 Segment,Segment 是 Druid 中数据存储、复制、均衡、以及计算的基本单元, Segment 由 dataSource_beginTime_endTime_version_shardNumber 唯一标识,1 个 segment 一般包含 5–10 million 行记录,大小一般在 300~700mb。
Segment 的存储格式
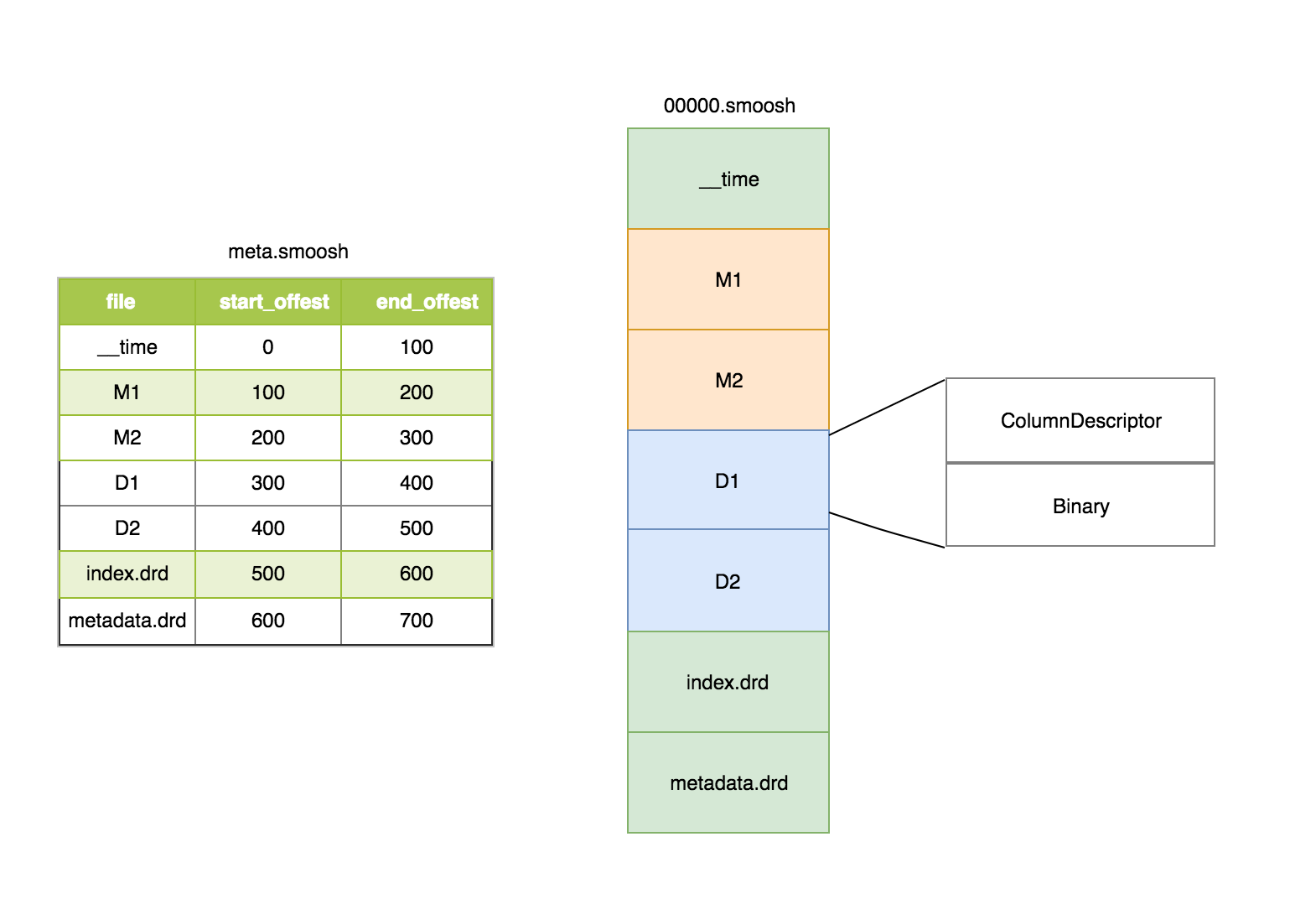
Druid segment 的存储格式如上图所示,包含 3 部分:
- version 文件
- meta 文件
- 数据文件
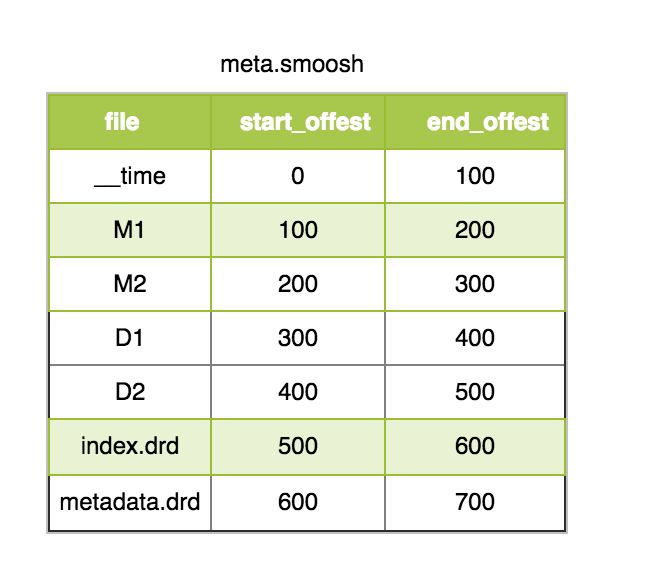
其中 meta 文件主要包含每 1 列的文件名和文件的偏移量。(注,druid 为了减少文件描述符,将 1 个 segment 的所有列都合并到 1 个大的 smoosh 中,由于 druid 访问 segment 文件的时候采用 MMap 的方式,所以单个 smoosh 文件的大小不能超过 2G,如果超过 2G,就会写到下一个 smoosh 文件)。
在 smoosh 文件中,数据是按列存储中,包含时间列,维度列和指标列,其中每 1 列会包含 2 部分:ColumnDescriptor 和 binary 数据。其中 ColumnDescriptor 主要保存每 1 列的数据类型和 Serde 的方式。
smoosh 文件中还有 index.drd 文件和 metadata.drd 文件,其中 index.drd 主要包含该 segment 有哪些列,哪些维度,该 Segment 的时间范围以及使用哪种 bitmap;metadata.drd 主要包含是否需要聚合,指标的聚合函数,查询粒度,时间戳字段的配置等。
指标列的存储格式
我们先来看指标列的存储格式:

指标列的存储格式如上图所示:
- version
- value 个数
- 每个 block 的 value 的个数(druid 对 Long 和 Float 类型会按 block 进行压缩,block 的大小是 64K)
- 压缩类型 (druid 目前主要有 LZ4 和 LZF 俩种压缩算法)
- 编码类型 (druid 对 Long 类型支持差分编码和 Table 编码两种方式,Table 编码就是将 long 值映射到 int,当指标列的基数小于 256 时,druid 会选择 Table 编码,否则会选择差分编码)
- 编码的 header (以差分编码为例,header 中会记录版本号,base value,每个 value 用几个 bit 表示)
- 每个 block 的 header (主要记录版本号,是否允许反向查找,value 的数量,列名长度和列名)
- 每 1 列具体的值
Long 型指标
Druid 中对 Long 型指标会先进行编码,然后按 block 进行压缩。编码算法包含差分编码和 table 编码,压缩算法包含 LZ4 和 LZF。
Float 型指标
Druid 对于 Float 类型的指标不会进行编码,只会按 block 进行压缩。
Complex 型指标
Druid 对于 HyperUnique,Cardinality,Histogram,Sketch 等复杂指标不会进行编码和压缩处理,每种复杂指标的 Serde 方式由每种指标自己的 ComplexMetricSerde 实现类实现。
String 维度的存储格式
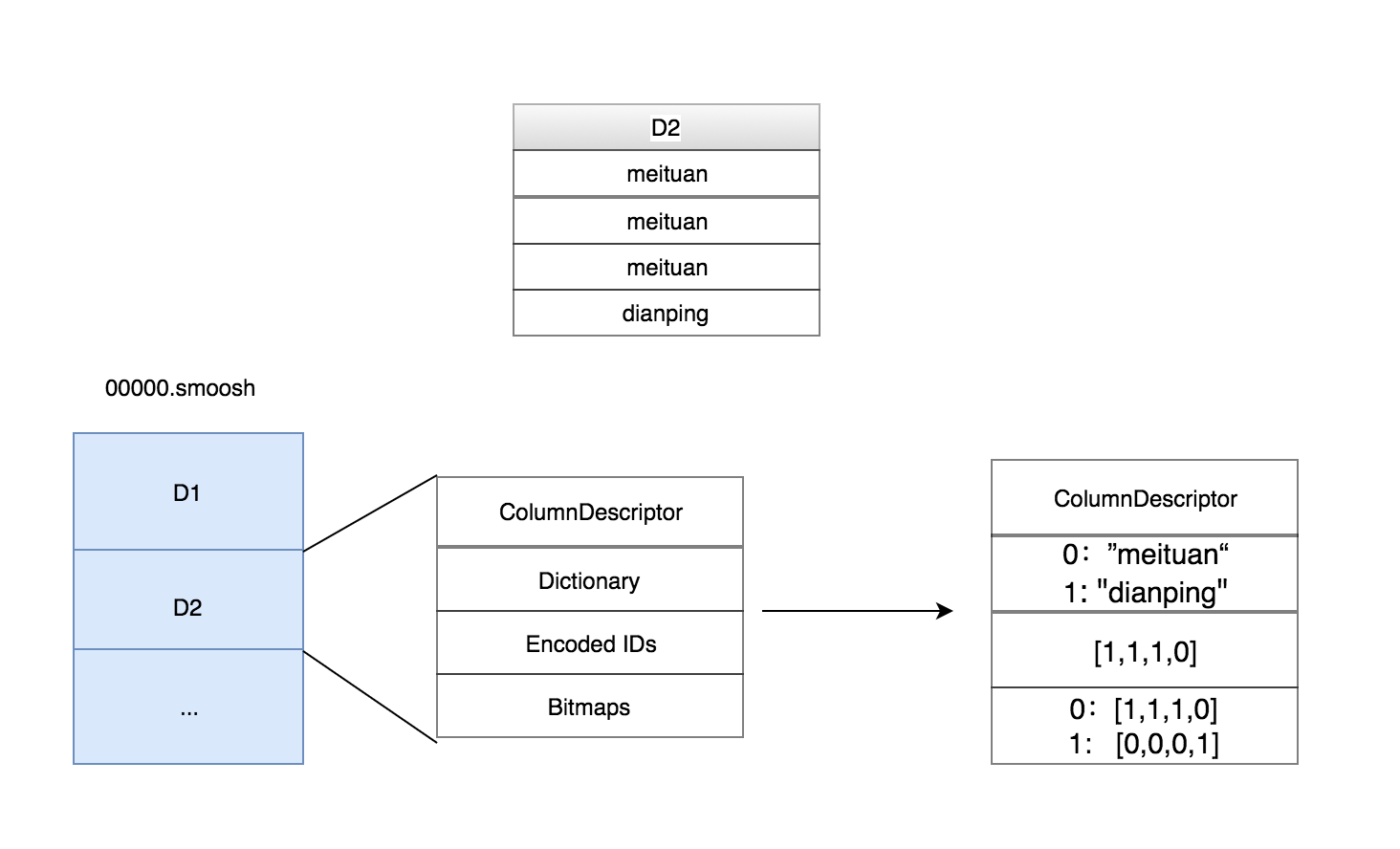
String 维度的存储格式如上图所示,前面提到过,时间列,维度列,指标列由两部分组成:ColumnDescriptor 和 binary 数据。 String 维度的 binary 数据主要由 3 部分组成:dict,字典编码后的 id 数组,用于倒排索引的 bitmap。
以上图中的 D2 维度列为例,总共有 4 行,前 3 行的值是 meituan,第 4 行的值是 dianing。Druid 中 dict 的实现十分简单,就是一个 hashmap。图中 dict 的内容就是将 meituan 编码为 0,dianping 编码为 1。 Id 数组的内容就是用编码后的 ID 替换掉原始值,所以就是 [1,1,1,0]。第 3 部分的倒排索引就是用 bitmap 表示某个值是否出现在某行中,如果出现了,bitmap 对应的位置就会置为 1,如图:meituan 在前 3 行中都有出现,所以倒排索引 1:[1,1,1,0] 就表示 meituan 在前 3 行中出现。
显然,倒排索引的大小是列的基数 * 总的行数,如果没有处理的话结果必然会很大。不过好在如果维度列如果基数很高的话,bitmap 就会比较稀疏,而稀疏的 bitmap 可以进行高效的压缩。
Segment 生成过程
- Add Row to Map
- Begin persist to disk
- Write version file
- Merge and write dimension dict
- Write time column
- Write metric column
- Write dimension column
- Write index.drd
- Merge and write bitmaps
- Write metadata.drd
Segment load 过程
- Read version
- Load segment to MappedByteBuffer
- Get column offset from meta
- Deserialize each column from ByteBuffer
Segment Query 过程
Druid 查询的最小单位是 Segment,Segment 在查询之前必须先 load 到内存,load 过程如上一步所述。如果没有索引的话,我们的查询过程就只能 Scan 的,遇到符合条件的行选择出来,但是所有查询都进行全表 Scan 肯定是不可行的,所以我们需要索引来快速过滤不需要的行。Druid 的 Segmenet 查询过程如下:
- 构造 1 个 Cursor 进行迭代
- 查询之前构造出 Fliter
- 根据 Index 匹配 Fliter,得到满足条件的 Row 的 Offset
- 根据每列的 ColumnSelector 去指定 Row 读取需要的列。
Druid 的编码和压缩
前面已经提到了,Druid 对 Long 型的指标进行了差分编码和 Table 编码,Long 型和 Float 型的指标进行了 LZ4 或者 LZF 压缩。
其实编码和压缩本质上是一个东西,一切熵增的编码都是压缩。 在计算机领域,我们一般把针对特定类型的编码称之为编码,针对任意类型的通用编码称之为压缩。
编码和压缩的本质就是让每一个 bit 尽可能带有更多的信息。