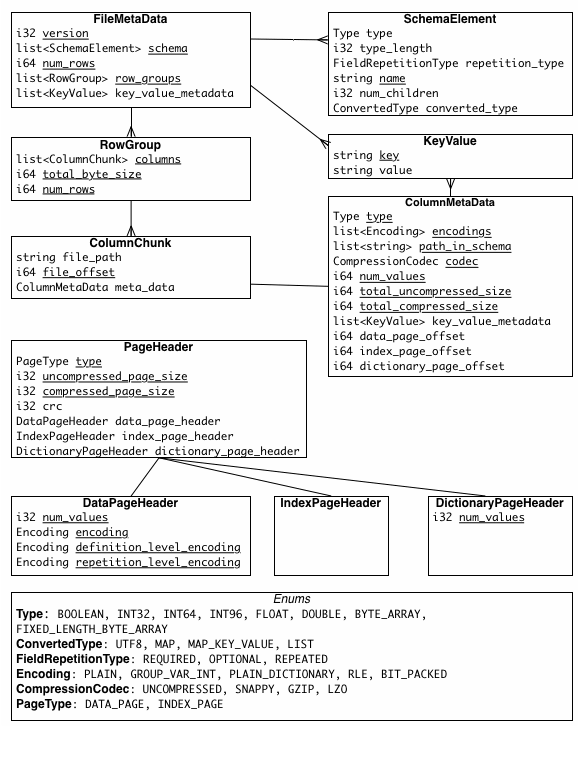
Row group: A logical horizontal partitioning of the data into rows. There is no physical structure that is guaranteed for a row group. A row group consists of a column chunk for each column in the dataset.
Column chunk: A chunk of the data for a particular column. These live in a particular row group and is guaranteed to be contiguous in the file.
Page: Column chunks are divided up into pages. A page is conceptually an indivisible unit (in terms of compression and encoding). There can be multiple page types which is interleaved in a column chunk.
一个文件由一个或者多个 row groups 组成, 一个 row group 包含一个 column chunk per column. column chunk 包含一个或者多个 pages.
/** * PageReader for a single column chunk. A column chunk contains * several pages, which are yielded one by one in order. * * This implementation is provided with a list of pages, each of which * is decompressed and passed through. */ staticfinalclassColumnChunkPageReaderimplementsPageReader{}
/** * Reader for a sequence a page from a given column chunk */ publicinterfacePageReader{
/** * @return the dictionary page in that chunk or null if none */ DictionaryPage readDictionaryPage();
/** * @return the total number of values in the column chunk */ longgetTotalValueCount();
/** * @return the next page in that chunk or null if after the last page */ DataPage readPage(); }
1 2 3 4
/** * The data for a column chunk */ privateclassChunk{}
1 2 3 4 5 6 7 8 9 10 11 12 13 14
/* * Builder to concatenate the buffers of the discontinuous parts for the same column. These parts are generated as a * result of the column-index based filtering when some pages might be skipped at reading. */ privateclassChunkListBuilder{ privateclassChunkData{ final List<ByteBuffer> buffers = new ArrayList<>(); OffsetIndex offsetIndex; }
/** * PageReader for a single column chunk. A column chunk contains * several pages, which are yielded one by one in order. * * This implementation is provided with a list of pages, each of which * is decompressed and passed through. */ staticfinalclassColumnChunkPageReaderimplementsPageReader{
privatefinal BytesInputDecompressor decompressor; privatefinallong valueCount; privatefinal List<DataPage> compressedPages; privatefinal DictionaryPage compressedDictionaryPage; // null means no page synchronization is required; firstRowIndex will not be returned by the pages privatefinal OffsetIndex offsetIndex; privatefinallong rowCount; privateint pageIndex = 0;
ColumnChunkPageReader(BytesInputDecompressor decompressor, List<DataPage> compressedPages, DictionaryPage compressedDictionaryPage, OffsetIndex offsetIndex, long rowCount) { this.decompressor = decompressor; this.compressedPages = new LinkedList<DataPage>(compressedPages); this.compressedDictionaryPage = compressedDictionaryPage; long count = 0; for (DataPage p : compressedPages) { count += p.getValueCount(); } this.valueCount = count; this.offsetIndex = offsetIndex; this.rowCount = rowCount; } }