Join 基础
Nested Loop Join
- 本质就是嵌套 for 循环
- 适用于被连接的数据子集较小
- Nested Loop先扫描外表, 每读取一条记录,就去去另一张表(内表, 一般是带索引的大表)里查找. 若没有索引的话一般就不会选择 Nested Loop Join(针对传统数据库).
Hash Join
- 大数据集连接时的常用方式, 可以减少一次 for 循环
- 优化器使用两个表中较小(相对较小)的表做 hash 表, 然后扫描较大的表并探测该 hash 表,找出与匹配的行。
- 适用于没有索引且较小的表完全可以放于内存中的情况
- Hash Join只能应用于等值连接
Merge Join
- for 循环次数同 Hash Join
- 排序两个表, 然后遍历第一个表, 在第二表中找对应的 key, 由于是排序的, 查找的复杂度会小于 O(n)
- 主要开销在排序, 如果表的 key 已经是排序的话, 开销比较小
Spark Join 框架
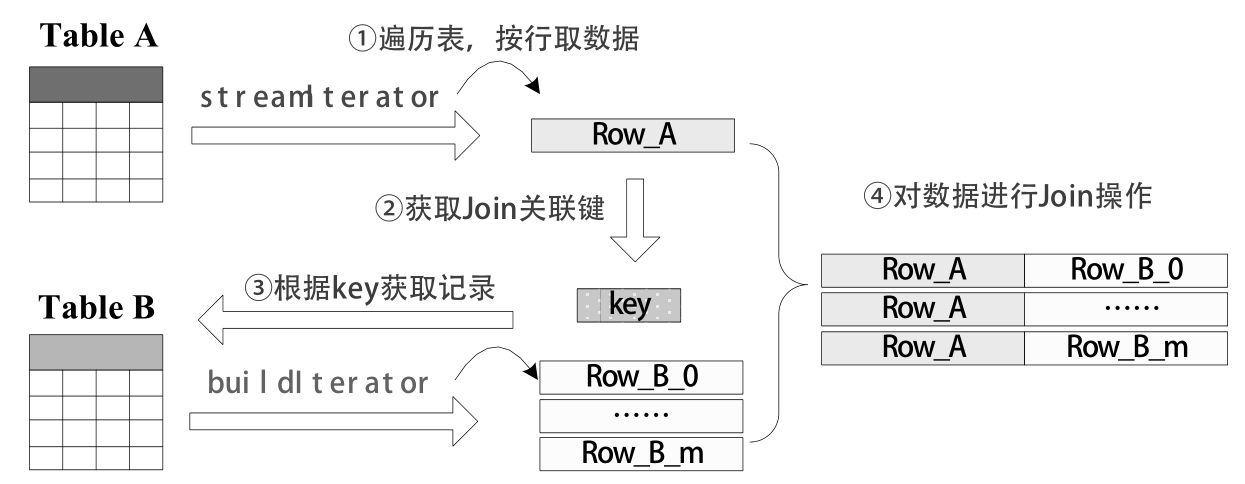
基本执行框架
- 参与Join操作的两张表分别被称为流式表(StreamTable)和构建表(BuildTable), 一般来说系统会默认将大表设定为流式表,将小表设定为构建表
无 Shuffle 的 join
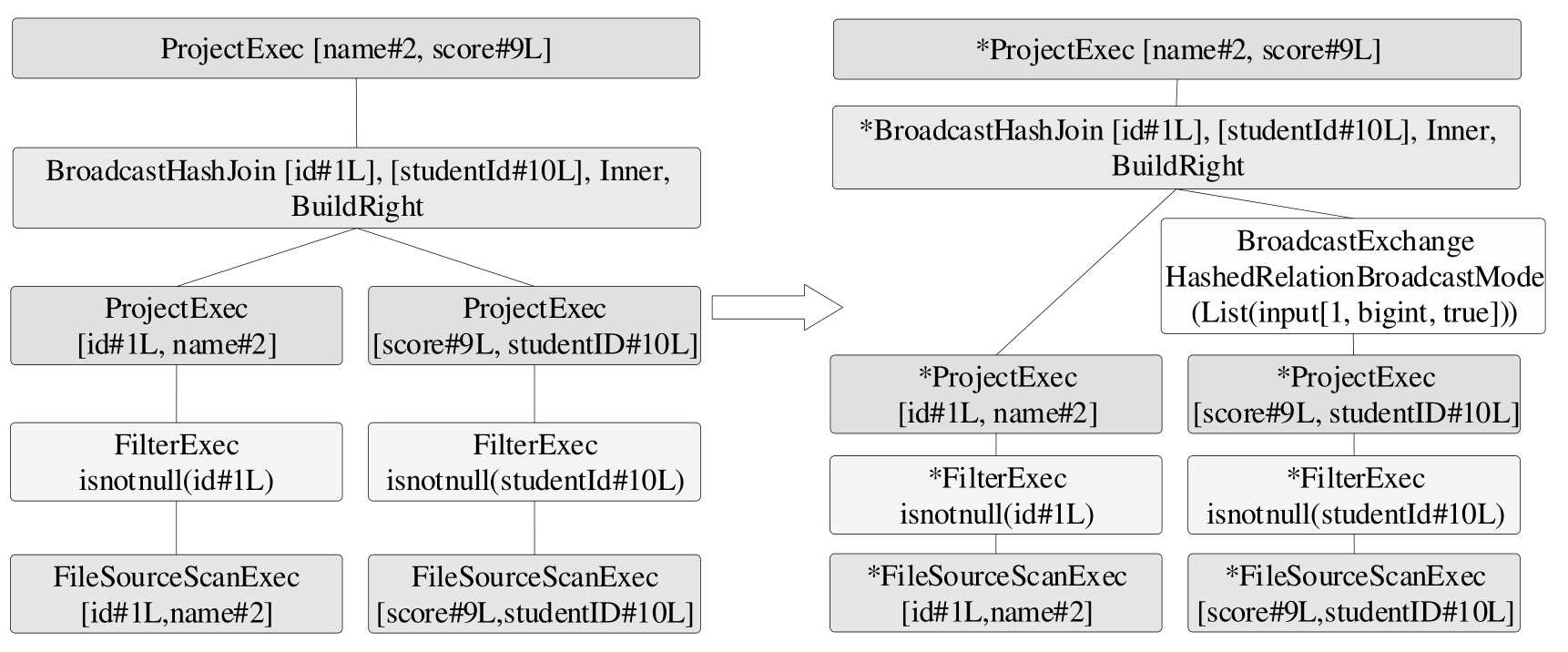
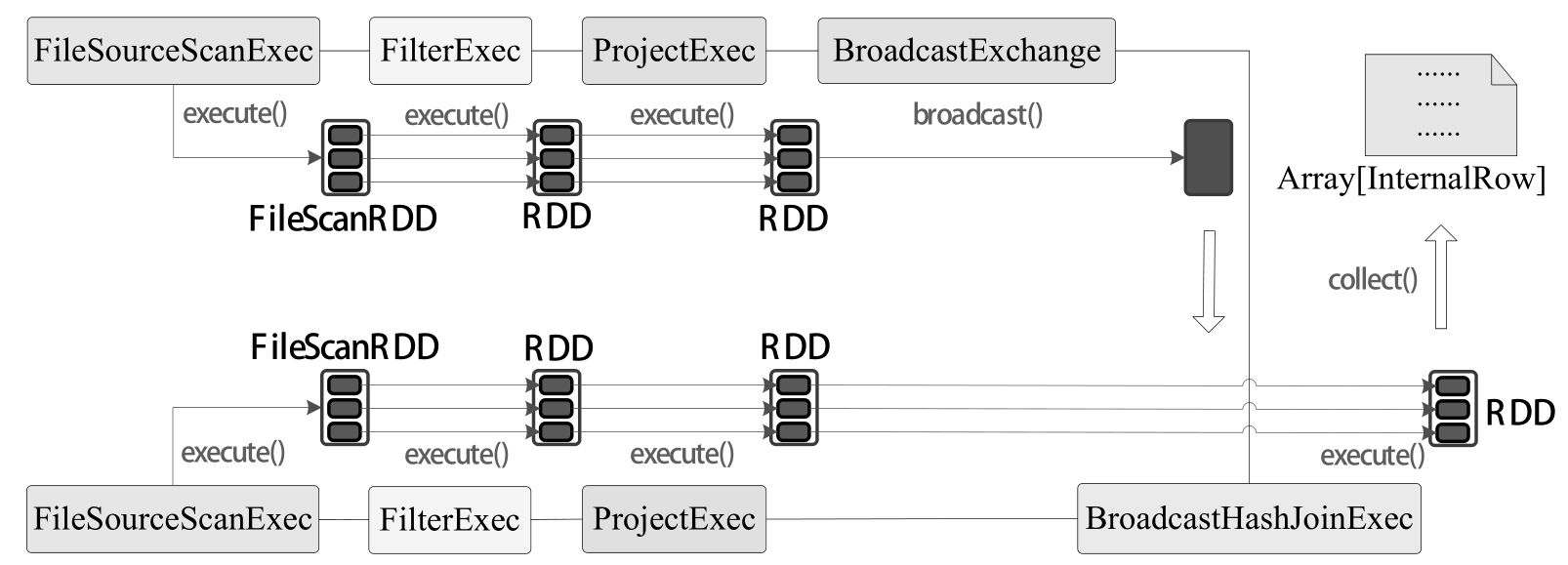
BroadcastJoinExec
通过将小表 broadcast 到每个 executor 节点上, 从而避免大表产生 shuffle.
选择条件
- 首先看有没有 hints, 如果有 hints, 直接选用 BHJ
- 如果能够广播非构建(build) 表,
JoinSelection#canBroadcast{ plan.stats.sizeInBytes <= conf.autoBroadcastJoinThreshold }, 默认 broadcast 的 threshold 是10Mb, 也会选用 BHJ.
缺点
- 每个 executor 上都会有一份表的数据, 有冗余
- 进行 broadcast 会拉数据到 driver 端, 对 driver 内存造成压力
有 Shuffle 的 join
在 Spark SQL 中, 最直观的进行 join 的操作如下:
- 对两个表分别对应 Join Key 进行 shuffle, 这样两个表上相同的 join key 的记录会在一个分区上, 方便进行 join 操作
- 对每个分区的记录进行 join(有Hash/Sort 两种方式, 下面介绍).
ShuffleHashJoinExec

在 shuffle 过后, 对每个分区中的小表构造出一张 hash 表
选择条件
- 当不 preferSortMergeJoin 时, 才会看下面的条件, 不然直接会用 SMJ
- 一边需要
canBuildLocalHashMap:plan.stats.sizeInBytes < conf.autoBroadcastJoinThreshold * conf.numShufflePartitions - 小表的数据量要比大表小很多
muchSmaller:a.stats.sizeInBytes * 3 <= b.stats.sizeInBytes - join cond 的key 没有排序
SortMergeJoinExec
选择条件
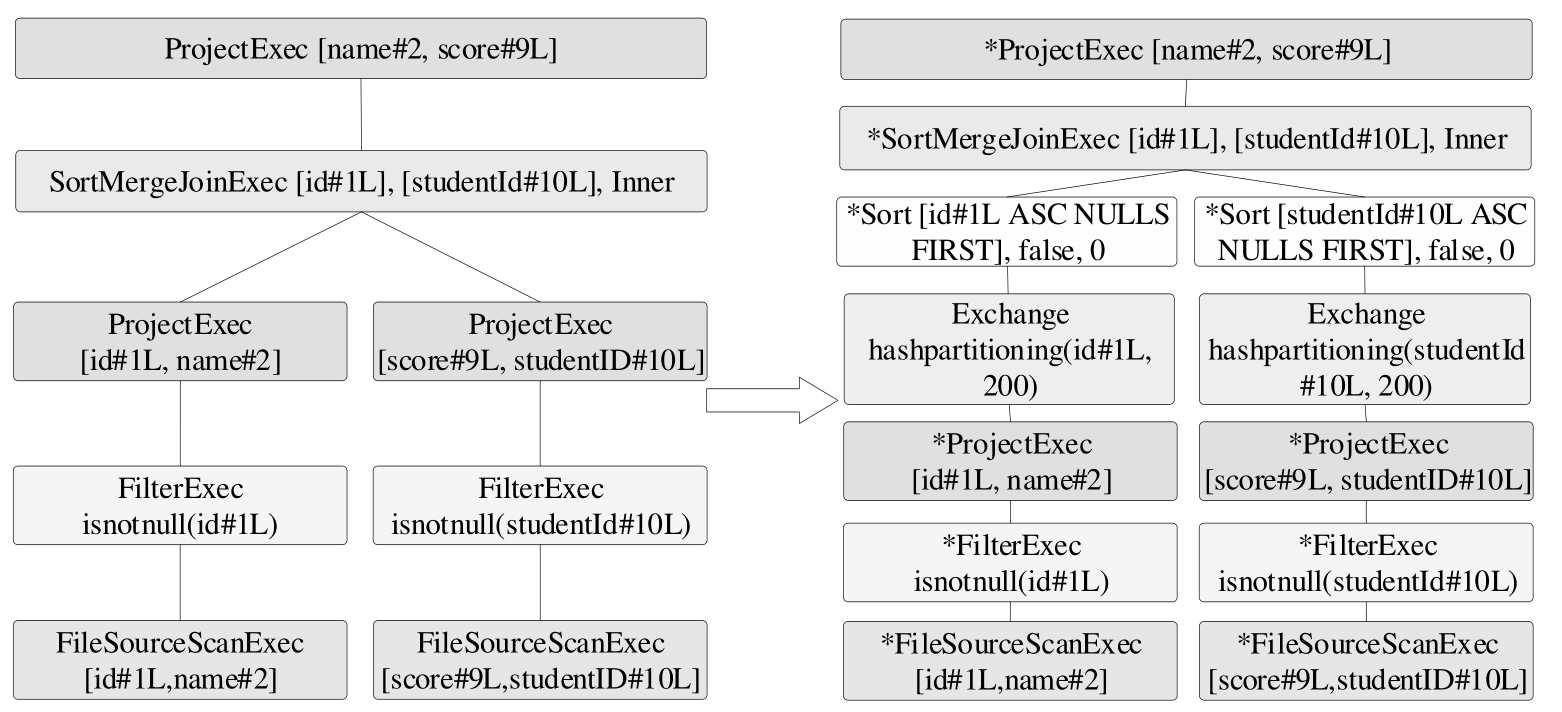
当两个表都较大时, 会选用这种 SMJ.
Spark Join Selection Code
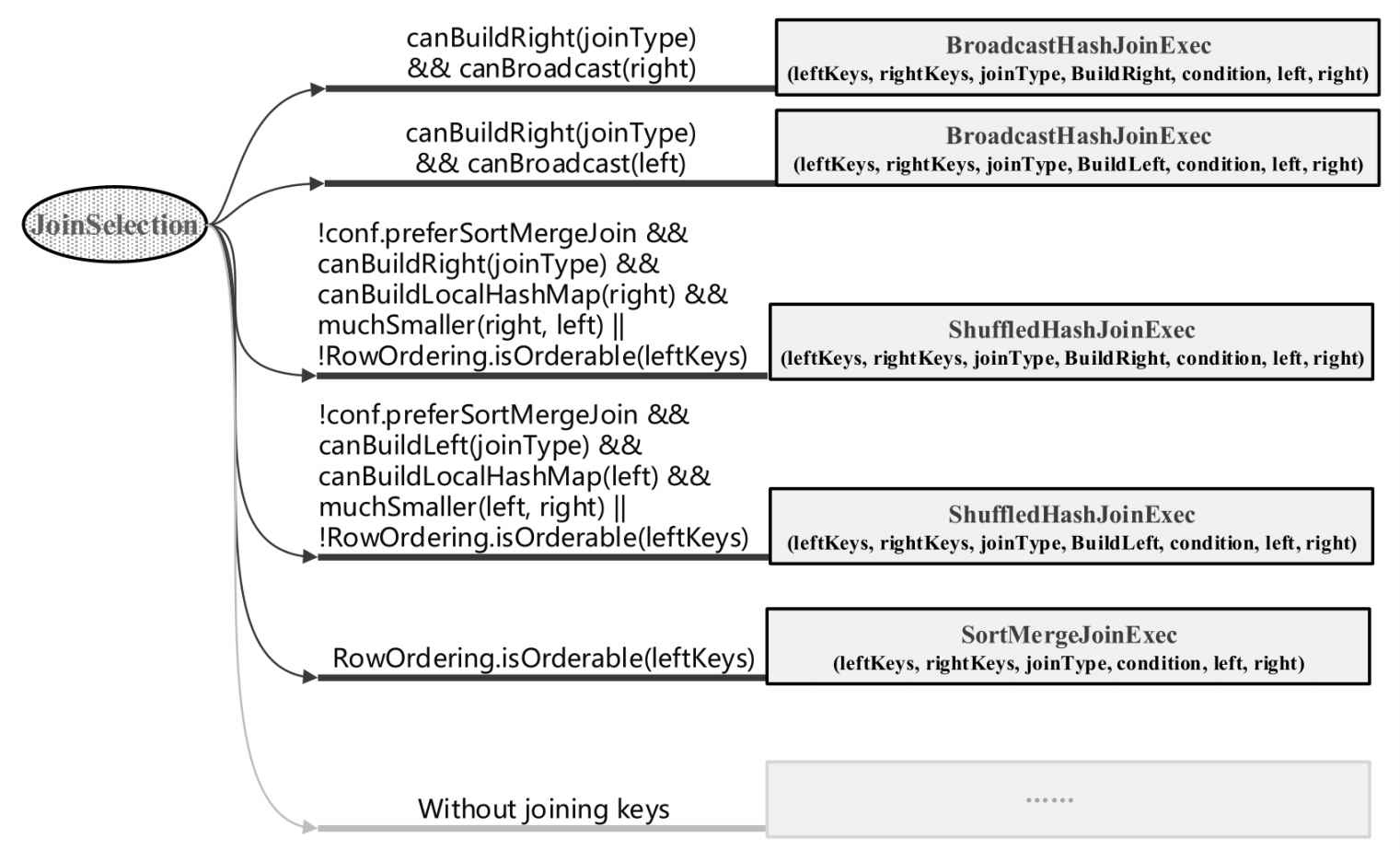
1 | def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match { |