优化器模型介绍 Cascade/Volcano Calcite Volcano Planner 的思想来自 Cascade/Volcano
Volcano Optimizer 将搜索分为两个阶段,在第一个阶段枚举所有逻辑等价的 Logical Algebra,而在第二阶段运用动态规划的方法自顶向下地搜索代价最小的 Physical Algebra
Cascades Optimizer 则将这两个阶段融合在一起,通过提供一个 Guidance 来指导 Rule 的执行顺序,在枚举逻辑等价算子的同时也进行物理算子的生成,这样做可以避免枚举所有的逻辑执行计划
Memo
Cascades Optimizer 在搜索的过程中,其搜索的空间
MEMO 的定义:是一种数据结构,用于管理一个组,每个组代表一个查询计划的不同子目标。
MEMO 结构的目标:是通过尽可能的公用相同的子树使得内存的使用最小。
MEMO 的主要思想:通过使用共享的副本来避免子树的重复使用。
Rule
Logical Algebra 之间的转换使用 Transformation Rule;
Logical Algebra 到 Physical Algebra 之间的转换使用 Implementation Rule
Physical Property 可以从 Physical Algebra 中提取,表示算子所产生的数的具有的物理属性,比如按照某个 Key 排序、按照某个 Key 分布在集群中等
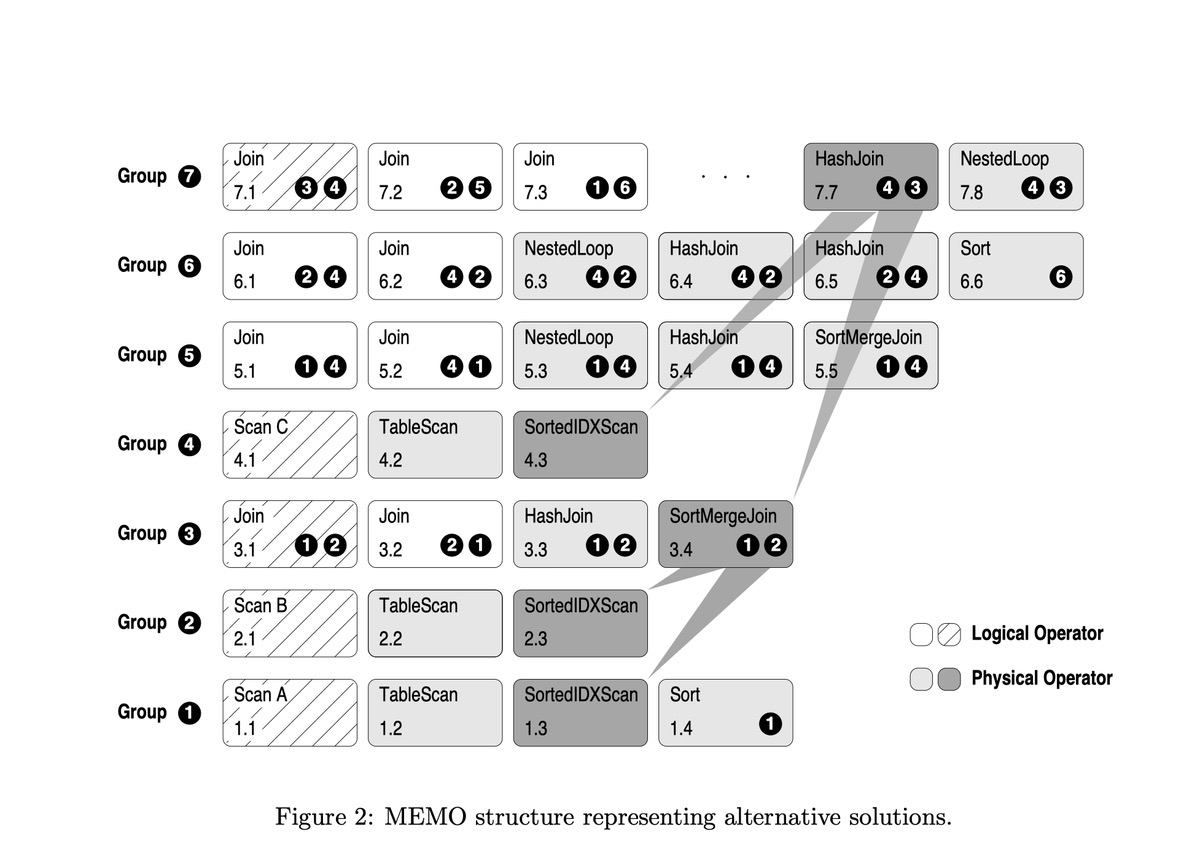
Memo 中两个最基本的概念就是 Expression Group(简称 Group) 以及 Group Expression(对应关系代数算子)
每个 Group 中保存的是逻辑等价的 Group Expression
Group Expression 的子节点是由 Group 组成
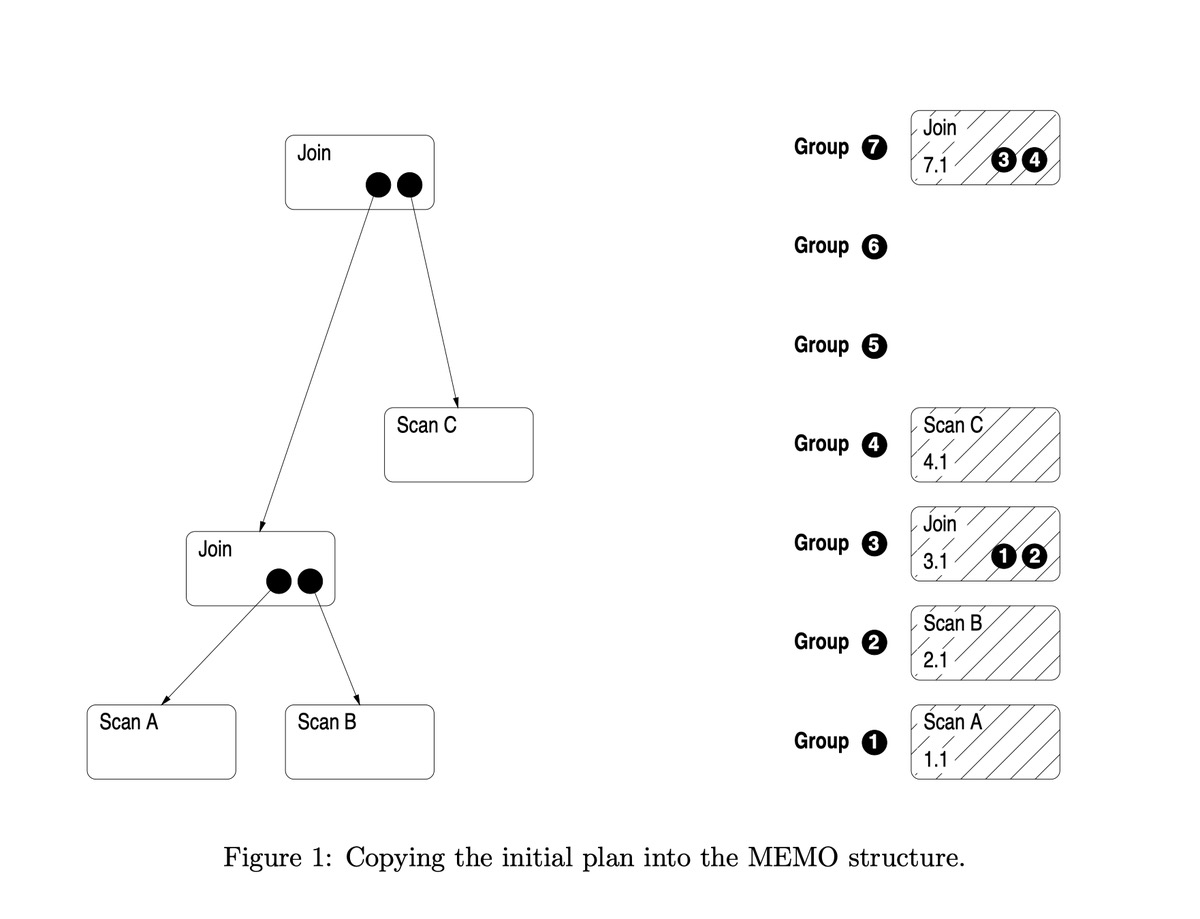
Init Memo
一旦最初的计划复制到了MEMO结构中以后,就可以对逻辑操作符做一些转换以生成物理操作符。
一个转换规则可以生成:
同一组中的一个逻辑操作符: 如 join( A, B) -> join( B, A)
同一组中的一个物理操作符: 如 join -> Hash Join
一组逻辑操作符组成一个子计划。根仍保留在原来的组中,而其他操作符分配到其他的组中,必要的时候可以建立新组,如 join( A, join(B,C)) -> join( join(A,B), C), 这两个最外面的 Join 是等价的, 所以是同一个根节点, 但是前后两次里面的 join 不一样, 所以在不同的组
由于物理属性的不同,同一组中的某些操作符可作为孩子节点,而另外一些操作符则不能
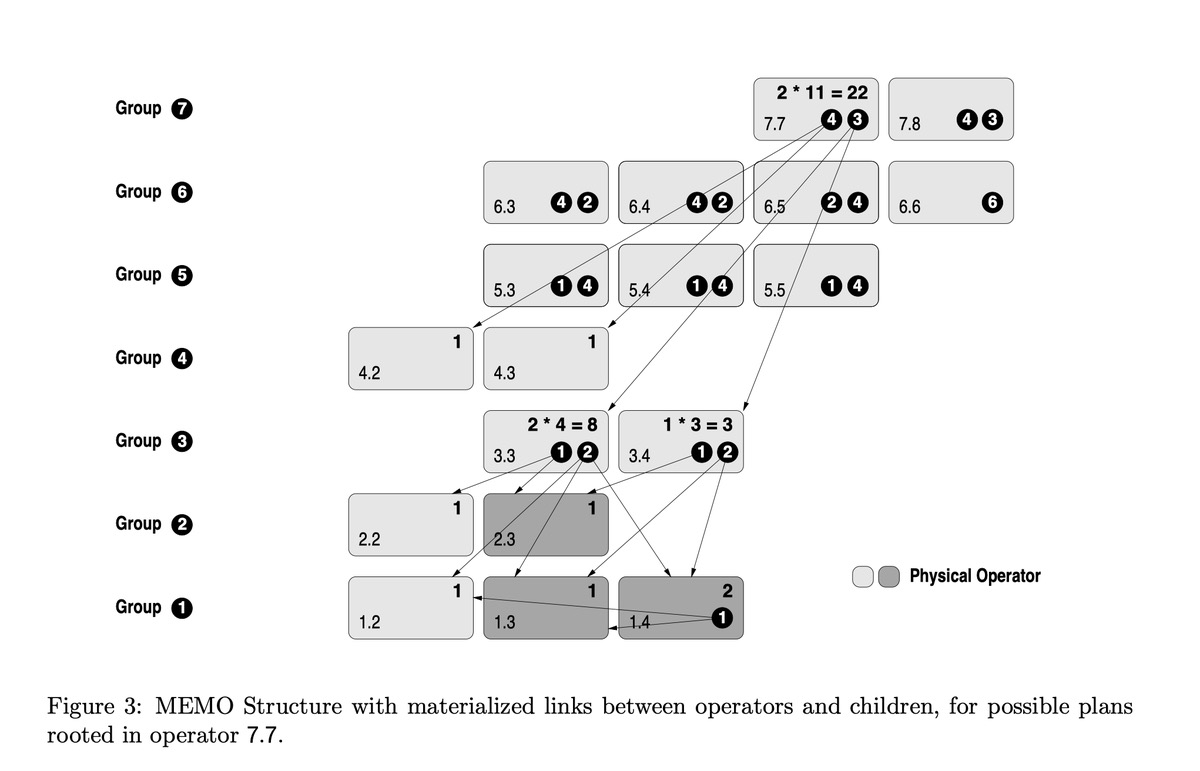
Find best plan
Ref:
[1]. [图片] Counting, Enumerating, and Sampling of Execution Plans in a Cost-Based Query Optimizer
[2]. The Cascades Framework for Query Optimization
[3]. Orca: A Modular Query Optimizer Architecture for Big Data
Calcite Volcano Planner 概念
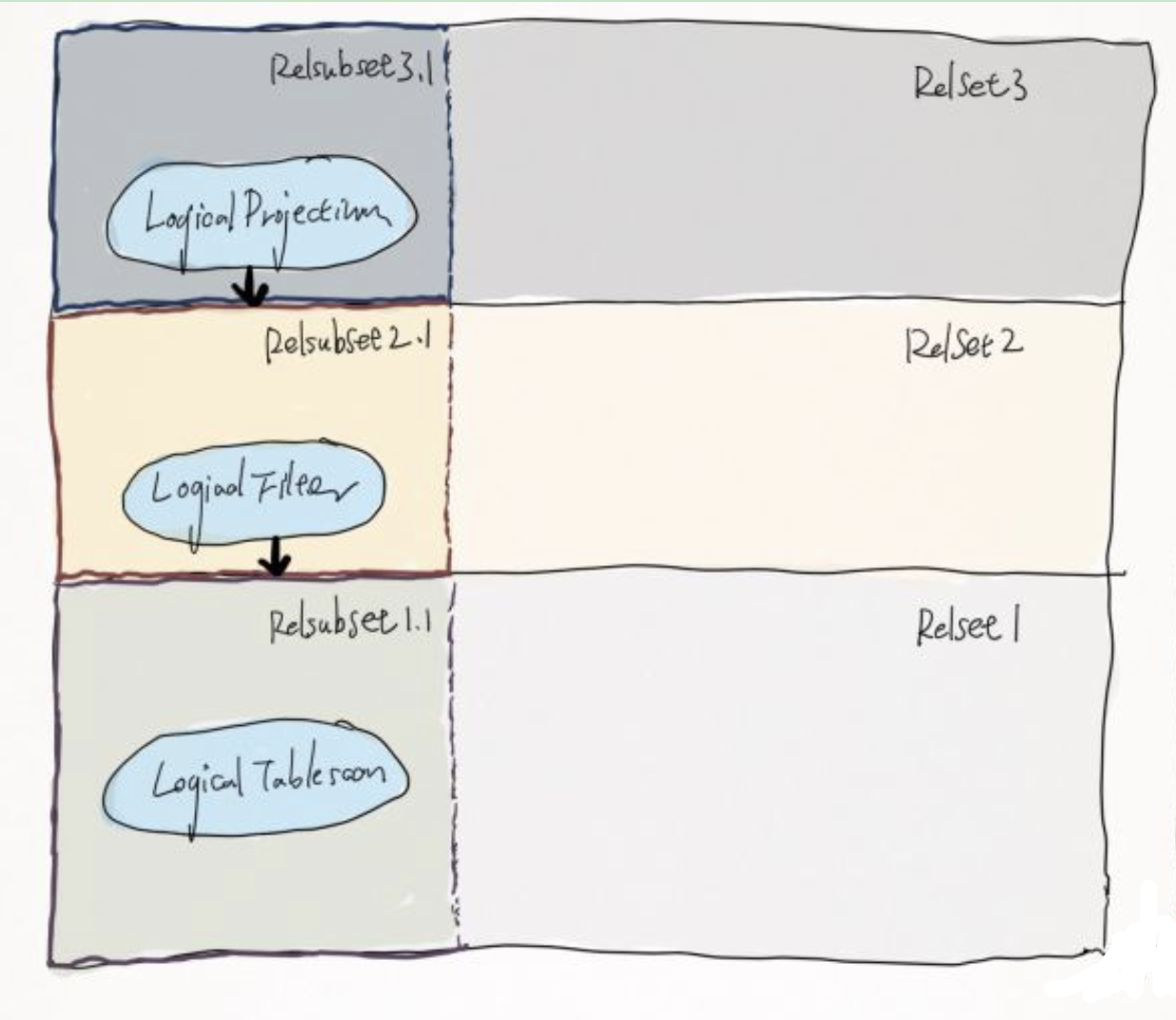
RelNode : Relation Expression, 逻辑执行计划的节点.
RelSet : 描述一组逻辑上相等的 RelNode 的集合
没有父类, 不是 **RelNode **!
所有的等价的 RelNode 会记录在 rels 中
一组等价关系表达式的集合, 语义相同, 但是其中的 RelNode 可以有不同的 Trait.
1 2 3 4 5 6 7 8 9 final List<RelNode> rels = new ArrayList<>();final List<RelNode> parents = new ArrayList<>();final List<RelSubset> subsets = new ArrayList<>();final List<AbstractConverter> abstractConverters = new ArrayList<>();
RelSubset : 描述一组物理上相等的 Relation Expression,即具有相同的 Physical Properties
也是一种 RelNode, 不是 RelSet !!!
在一个 RelSet 中相同的 RelTraitSet 的 RelNode 会在同一个 RelSubSet 内
添加一个 Rel 到 RelSubset 会添加 rel 到对应的 RelSet 中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 RelOptCost bestCost; final RelSet set; RelNode best; protected RelTraitSet traitSet; public Iterable<RelNode> getRels () return () -> Linq4j.asEnumerable(set.rels) .where(v1 -> v1.getTraitSet().satisfies(traitSet)) .iterator(); }
一个 RelSet 有一组 RelSubset, 而一个 RelSubset 引用一个 RelSet.
一个 RelSet 可能有多种 trait (因为一组 RelNode 逻辑上等价, 物理上(trait) 不等价), 比如 在 [X] , [Y, Z] 上都进行了排序, 那么对于这个 RelSet 有两个 RelSubset
通过 getRels 符合自己 trait 的 rels.
VolcanoRuleMatch/RuleCall :描述一次成功规则的匹配,包含 Rule 和被匹配的节点
RuleQueue :是一个优先队列,包含当前所有可行的 RuleMatch
Importance :描述 RuleMatch 的重要程度,importance 大的优先处理, 每一轮迭代都会实时调整.
尽量对代价大的节点先做优化,从而尽可能在有限的优化次数内获得更大的收益, ost 越大、importance 也越大
Program : 用来组装优化的流程, 类似 pipeline 的感觉.
调用约定概念梳理 Calite 的特有概念, 为了支持多数据源(异构数据源)
Convention
一种 RelTrait, 表一个物理实现
几种实现
Convention#Impl: 默认的 Convention, 只是提供了接口信息和名称信息 e.g.
Convention NONE = new Impl("NONE", RelNode.class);SparkRel.CONVENTION: new Convention.Impl("SPARK", SparkRel.class);
EnumerableConvention: 能返回 linq4j.Enumerable 的 Convention 实现, 默认一般用这个, 会使用 codegen.
InterpretableConvention: 也是返回 Enumerable, 同样会实现 EnumerableRel 接口, 不通过 codegen 执行
JdbcConvention,
BindableConvention
ConverterRule:
是 RelOptRule 的子类, 专门用来做数据源之间的转换
ConverterRule 一般会调用对应的 Converter 来完成工作, 比如说 JdbcToSparkConverterRule 调用 JdbcToSparkConverter 来完成对 JDBC Table 到 Spark RDD 的转换
Abstract base class for a rule which converts from one calling convention to another without changing semantics.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 static class SparkToEnumerableConverterRule extends ConverterRule public static final SparkToEnumerableConverterRule INSTANCE = new SparkToEnumerableConverterRule(); private SparkToEnumerableConverterRule () super ( RelNode.class, SparkRel.CONVENTION, EnumerableConvention.INSTANCE, "SparkToEnumerableConverterRule" ); } @Override public RelNode convert (RelNode rel) return new SparkToEnumerableConverter(rel.getCluster(), rel.getTraitSet().replace(EnumerableConvention.INSTANCE), rel); } }
Converter:
一种特殊的 RelNode (这是一个 RelNode )
后续用 ExpandConversionRule 来调用 TraitDef 的 convert 来做转换, 关于 convention, 需要 isGuaranteed 为 true, 但是在 calcite 代码里并没有这个转换, 其他使用 Calcite 的引擎有, 如 Drill.
由 Converter Rule 转化而成
举个例子: SparkToEnumerableConverterRule 实现了 SparkRel.CONVENTION 到 EnumerableConvention 的转换,生成了SparkToEnumerableConverter , 对应没有这一套是会生成一个AbstractConverter 在根节点, 所以他们的子节点的 trait (Convention) 会以他们为准(ENUMERABLE/SPARK).
再次强调这个 SparkToEnumerableConverter 是一个 RelNode, 可以看看这个节点怎么生成物理执行计划:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public Result implement (EnumerableRelImplementor implementor, Prefer pref) final BlockBuilder list = new BlockBuilder(); final SparkRel child = (SparkRel) getInput(); final PhysType physType = PhysTypeImpl.of(implementor.getTypeFactory(), getRowType(), JavaRowFormat.CUSTOM); SparkRel.Implementor sparkImplementor = new SparkImplementorImpl(implementor); final SparkRel.Result result = child.implementSpark(sparkImplementor); final Expression rdd = list.append("rdd" , result.block); final Expression enumerable = list.append( "enumerable" , Expressions.call( SparkMethod.AS_ENUMERABLE.method, rdd)); list.add(Expressions.return_(null , enumerable)); return implementor.result(physType, list.toBlock()); }
SparkMethod.AS_ENUMERABLE.method :
1 AS_ENUMERABLE(SparkRuntime.class, "asEnumerable" , JavaRDD.class)
在 SparkRuntime 类中可以找到 asEnumerable 方法:
1 2 3 4 public static <T> Enumerable<T> asEnumerable (JavaRDD<T> rdd) { return Linq4j.asEnumerable(rdd.collect()); }
基本流程 入口点 测试 SQL: select * from emps where name = ‘John’
1. Prepare
看代码中最后的 return 语句, 加进来了一系列的优化:
Hep Planner 做一些子查询的优化 (SubQueryRemoveRule.FILTER, SubQueryRemoveRule.PROJECT, SubQueryRemoveRule.JOIN)
DecorrelateProgram/TrimFieldsProgram
Volcano Planner , 默认会注册一些 rule, 在 RelOptUtil#registerDefaultRulesHep Planner# RelOptRules.CALC_RULES
对 VolcanoPlanner 的使用就是在第3步, 我们主要关注这一步
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 protected RelRoot optimize (RelRoot root) final Program program = getProgram(); final RelNode rootRel4 = program.run(planner, root.rel, desiredTraits, materializationList, latticeList); } public static Program standard (RelMetadataProvider metadataProvider) final Program program1 = (planner, rel, requiredOutputTraits, materializations, lattices) -> { planner.setRoot(rel); for (RelOptMaterialization materialization : materializations) { planner.addMaterialization(materialization); } for (RelOptLattice lattice : lattices) { planner.addLattice(lattice); } final RelNode rootRel2 = rel.getTraitSet().equals(requiredOutputTraits) ? rel : planner.changeTraits(rel, requiredOutputTraits); assert rootRel2 != null ; planner.setRoot(rootRel2); final RelOptPlanner planner2 = planner.chooseDelegate(); final RelNode rootRel3 = planner2.findBestExp(); assert rootRel3 != null : "could not implement exp" ; return rootRel3; }; return sequence(subQuery(metadataProvider), new DecorrelateProgram(), new TrimFieldsProgram(), program1, calc(metadataProvider)); }
set default rule/trait CalcitePrepareImpl#createPlanner
1 2 3 4 5 6 7 8 final VolcanoPlanner planner = new VolcanoPlanner(costFactory, externalContext);planner.addRelTraitDef(ConventionTraitDef.INSTANCE); if (CalciteSystemProperty.ENABLE_COLLATION_TRAIT.value()) { planner.addRelTraitDef(RelCollationTraitDef.INSTANCE); } RelOptUtil.registerDefaultRules(planner,prepareContext.config().materializationsEnabled(), enableBindable);
VolcanoPlanner#addRule
在优化时,哪个 RelNode 可以应用哪些 Rule 都已经提前记录好了, 是一个 MultiMap,一个RelNode 可以对应于多个 operands.
后面还会调用 rule 的 onMatch 进行筛选, 这里只是很粗粒度的
1 2 3 4 5 6 7 for (RelOptRuleOperand operand : rule.getOperands()) { for (Class<? extends RelNode> subClass: subClasses(operand.getMatchedClass())) { classOperands.put(subClass, operand); } }
match 的具体位置在:
org.apache.calcite.plan.volcano.VolcanoRuleCall#matchRecurse
1 2 3 4 5 ... if (getRule().matches(this )) { onMatch(); } ...
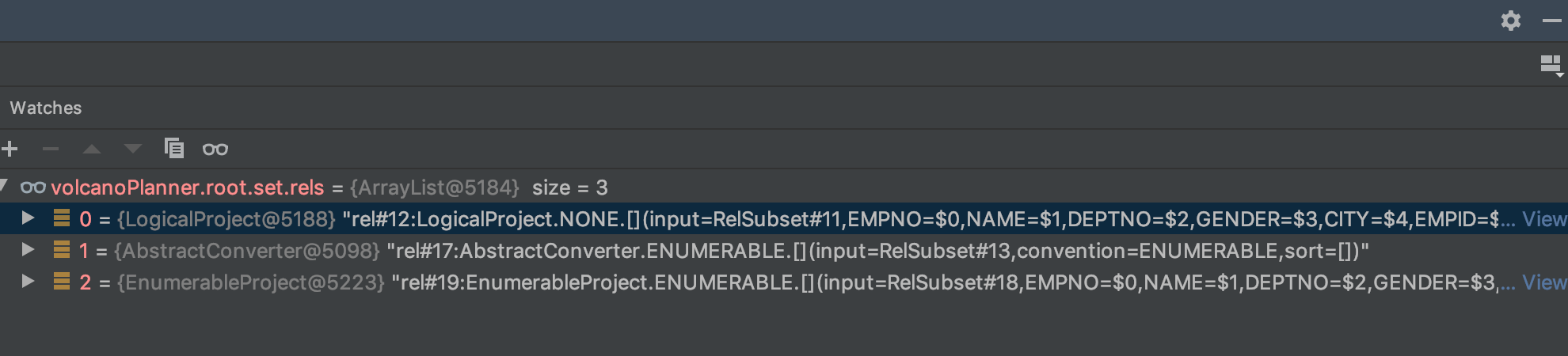
setRoot (1st) 初始进入 optimizer 时的执行计划的 dump plan:
1 2 3 LogicalProject(EMPNO= [$0 ], NAME= [$1 ], DEPTNO= [$2 ], GENDER= [$3 ], CITY= [$4 ], EMPID= [$5 ], AGE= [$6 ], SLACKER= [$7 ], MANAGER= [$8 ], JOINEDAT= [$9 ]) LogicalFilter(condition = [= ($1 , 'John' )]) LogicalTableScan(table = [[SALES, EMPS]])
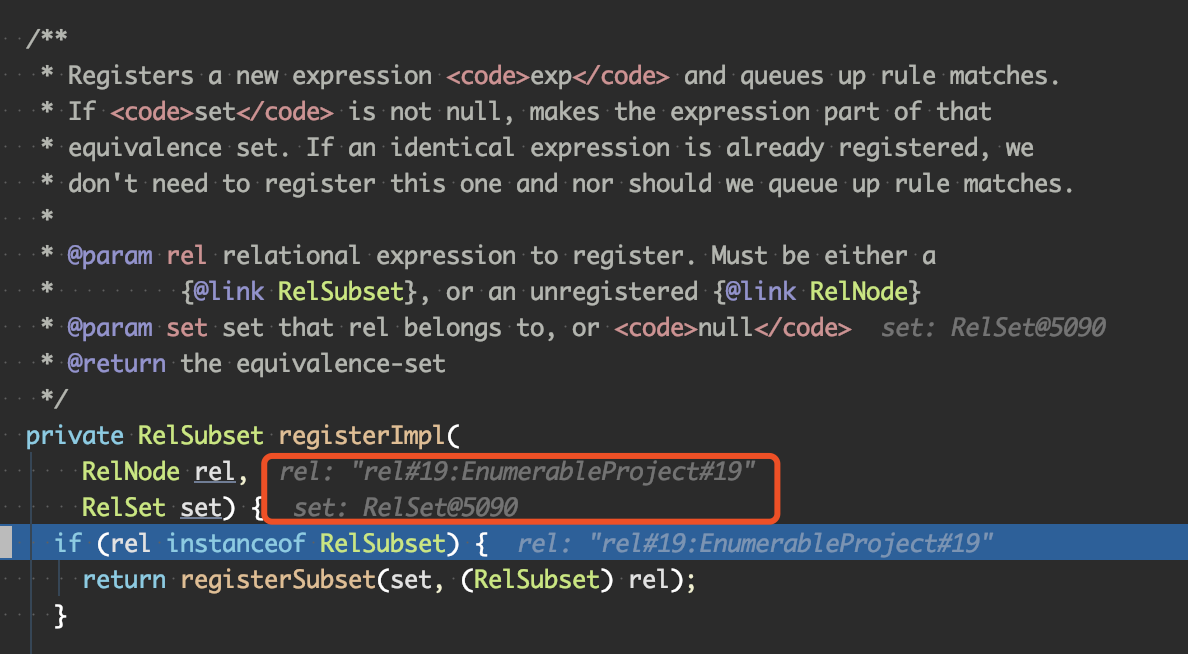
核心方法是 registerImpl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 public void setRoot (RelNode rel) this .root = registerImpl(rel, null ); if (this .originalRoot == null ) { this .originalRoot = rel; } this .ruleQueue.recompute(this .root); ensureRootConverters(); } private RelSubset registerImpl ( RelNode rel, RelSet set) ... if (rel instanceof RelSubset) { return registerSubset(set, (RelSubset) rel); } rel = rel.onRegister(this ); if (set == null ) { set = new RelSet( nextSetId++, Util.minus( RelOptUtil.getVariablesSet(rel), rel.getVariablesSet()), RelOptUtil.getVariablesUsed(rel)); this .allSets.add(set); } RelSubset subset = addRelToSet(rel, set); ... fireRules(rel, true ); if (set.subsets.size() > subsetBeforeCount) { fireRules(subset, true ); } return subset; } private RelSubset addRelToSet (RelNode rel, RelSet set) RelSubset subset = set.add(rel); mapRel2Subset.put(rel, subset); final RelMetadataQuery mq = rel.getCluster().getMetadataQuery(); try { subset.propagateCostImprovements(this , mq, rel, new HashSet<>()); } catch (CyclicMetadataException e) { } return subset; }
onRegister
注意, 这里更新了 RelNode 的 input 为 RelSubSet(ensureRegistered).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public RelNode onRegister (RelOptPlanner planner) List<RelNode> oldInputs = getInputs(); List<RelNode> inputs = new ArrayList<>(oldInputs.size()); for (final RelNode input : oldInputs) { RelNode e = planner.ensureRegistered(input, null ); inputs.add(e); } RelNode r = this ; if (!Util.equalShallow(oldInputs, inputs)) { r = copy(getTraitSet(), inputs); } r.recomputeDigest(); assert r.isValid(Litmus.THROW, null ); return r; }
ensureRegistered
输入是两个等价的 RelNode, 返回一个 RelSubset
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public RelSubset ensureRegistered (RelNode rel, RelNode equivRel) RelSubset result; final RelSubset subset = getSubset(rel); if (subset != null ) { if (equivRel != null ) { final RelSubset equivSubset = getSubset(equivRel); if (subset.set != equivSubset.set) { merge(equivSubset.set, subset.set); } } result = subset; } else { result = register(rel, equivRel); } if (LOGGER.isDebugEnabled()) { assert isValid (Litmus.THROW) } return result; }
fireRules
上面的 fireRules deferred 为是 true, 意思就是不立即执行 rule, 可以看到DeferringRuleCall#onMatch 把 VolcanoRuleMatch 扔到了 rule queue 中, 等之后执行.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 void fireRules ( RelNode rel, boolean deferred) for (RelOptRuleOperand operand : classOperands.get(rel.getClass())) { if (operand.matches(rel)) { final VolcanoRuleCall ruleCall; if (deferred) { ruleCall = new DeferringRuleCall(this , operand); } else { ruleCall = new VolcanoRuleCall(this , operand); } ruleCall.match(rel); } } } private static class DeferringRuleCall extends VolcanoRuleCall DeferringRuleCall( VolcanoPlanner planner, RelOptRuleOperand operand) { super (planner, operand); } protected void onMatch () final VolcanoRuleMatch match = new VolcanoRuleMatch( volcanoPlanner, getOperand0(), rels, nodeInputs); volcanoPlanner.ruleQueue.addMatch(match); } }
总结:
输入是一颗 RelNode 的树, setRoot 是深度遍历, 将每个 RelNode 创建一个 RelSet 和一个包含初始 RelNode 的 RelSubSet, 并且把节点所能执行的 Rule 作为一个 VolcanoRuleCall 放入 RuleQueue. 最终生成的是一颗 RelSet 组成的树(子树在 RelSet.rels (RelNode#getInput), input 是 RelSubSet, RelSubSet 又记录了 RelSet, 以此类推, 构成一棵树)
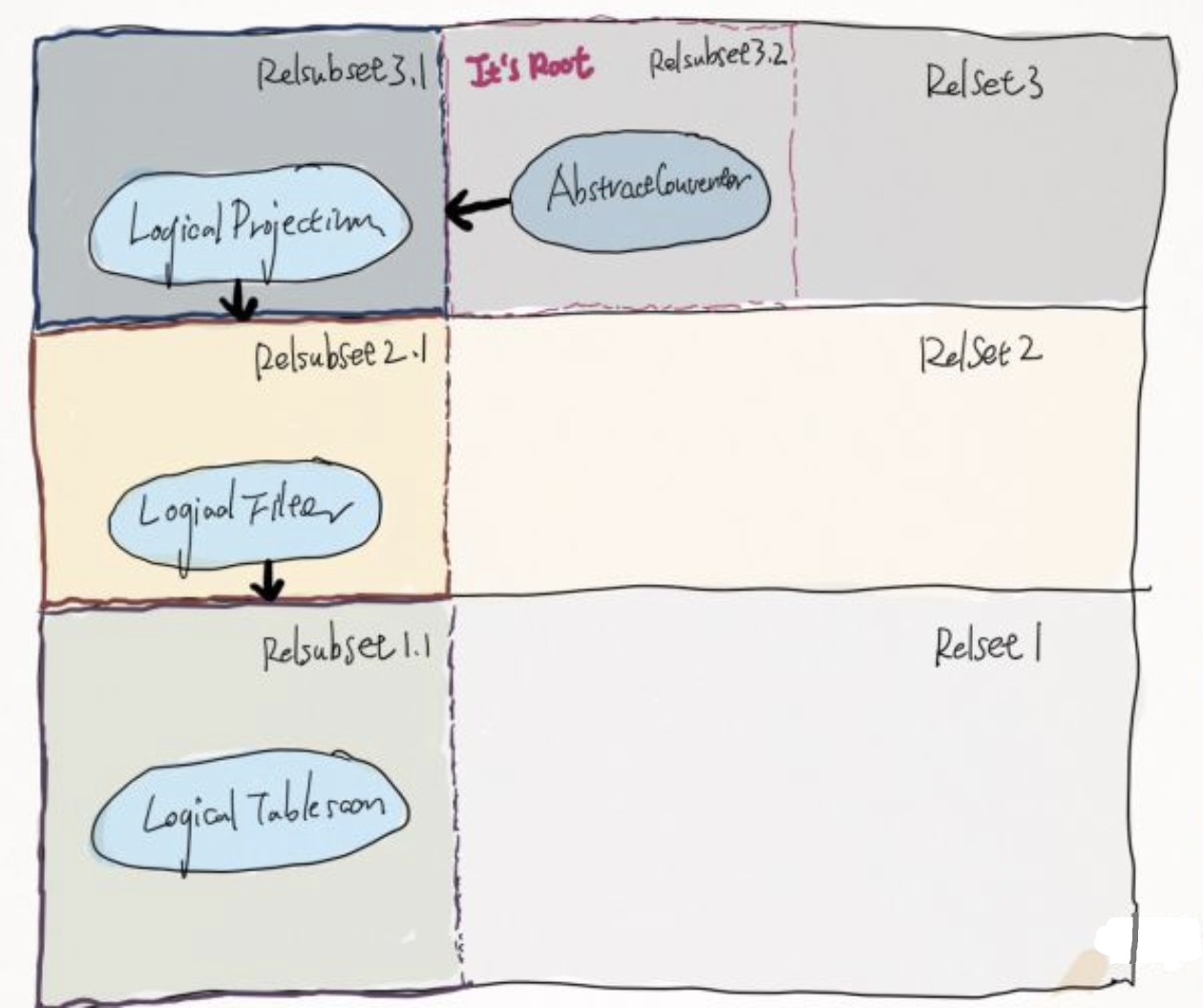
setRoot (2st) 首先会进行 RelNode rootRel2 = planner.changeTraits(rel, requiredOutputTraits)
1 2 3 4 5 6 7 public RelNode changeTraits (final RelNode rel, RelTraitSet toTraits) RelSubset rel2 = ensureRegistered(rel, null ); if (rel2.getTraitSet().equals(toTraits)) { return rel2; } return rel2.set.getOrCreateSubset(rel.getCluster(), toTraits.simplify()); }
在 changeTraits 里会创建一个新的 RelSubset(rel#16:Subset#2.ENUMERABLE.[]) 作为根节点(rootRel2), 但是两者还是同一个 RelSet (因为逻辑语义上没有变化)
然后会再用这个 rootRel2 再 set 一次 root: planner.setRoot(rootRel2); 由于这次的根节点是 RelSubset, registerImpl 会走到 registerSubset 中去. 不过会直接返回出来.
接着会执行 ensureRootConverters , 这里发现当root 的traitSet 和 root 的 subset 的 traitSet 不想等的时候, 会添加一个 AbstractConverter 节点. 注意这个 AbstractConverter 是一个 RelNode.
1 2 3 4 5 6 7 8 9 10 void ensureRootConverters () final Set<RelSubset> subsets = new HashSet<>(); for (RelSubset subset : root.set.subsets) { final ImmutableList<RelTrait> difference = root.getTraitSet().difference(subset.getTraitSet()); if (difference.size() == 1 && subsets.add(subset)) { register(new AbstractConverter(subset.getCluster(), subset, difference.get(0 ).getTraitDef(), root.getTraitSet()), root); } } }
在这里会再一次的调用到 registerImpl, 不过这次 RelSet 已经不为空了.
在 registerImpl 中, 当发现节点是 Converter 时, 会尝试把 Converter merge 到其 child 所在是 RelSet 中(Converters are in the same set as their children. ).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 private RelSubset registerImpl (RelNode rel, RelSet set) if (rel instanceof Converter) { final RelNode input = ((Converter) rel).getInput(); final RelSet childSet = getSet(input); if ((set != null ) && (set != childSet) && (set.equivalentSet == null )) { LOGGER.trace("Register #{} {} (and merge sets, because it is a conversion)" , rel.getId(), rel.getDigest()); merge(set, childSet); registerCount++; } else { set = childSet; } } }
这是经过第二次 set root 之后的树的关系
整个过程 的 log:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 TRACE - new RelSubset#9 TRACE - Register rel#0:LogicalTableScan.NONE.[](table=[SALES, EMPS]) in rel#9:Subset#0.NONE.[] TRACE - Importance of [rel#9:Subset#0.NONE.[]] is 0.0 TRACE - OPTIMIZE Rule-match queued: rule [EnumerableTableScanRule] rels [rel#0:LogicalTableScan.NONE.[](table=[SALES, EMPS])] TRACE - OPTIMIZE Rule-match queued: rule [BindableTableScanRule] rels [rel#0:LogicalTableScan.NONE.[](table=[SALES, EMPS])] TRACE - OPTIMIZE Rule-match queued: rule [TableScanRule] rels [rel#0:LogicalTableScan.NONE.[](table=[SALES, EMPS])] TRACE - new LogicalFilter#10 TRACE - new RelSubset#11 TRACE - Register rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John')) in rel#11:Subset#1.NONE.[] TRACE - Importance of [rel#9:Subset#0.NONE.[]] to its parent [rel#11:Subset#1.NONE.[]] is 0.0 (parent importance=0.0, child cost=1.0E30, parent cost=1.0E30) TRACE - Importance of [rel#9:Subset#0.NONE.[]] is 0.0 TRACE - Importance of [rel#11:Subset#1.NONE.[]] is 0.0 TRACE - OPTIMIZE Rule-match queued: rule [EnumerableFilterRule] rels [rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John'))] TRACE - OPTIMIZE Rule-match queued: rule [FilterTableScanRule] rels [rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John')), rel#0:LogicalTableScan.NONE.[](table=[SALES, EMPS])] TRACE - OPTIMIZE Rule-match queued: rule [MaterializedViewJoinRule(Filter)] rels [rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John'))] TRACE - OPTIMIZE Rule-match queued: rule [MaterializedViewFilterScanRule] rels [rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John')), rel#0:LogicalTableScan.NONE.[](table=[SALES, EMPS])] TRACE - new LogicalProject#12 TRACE - new RelSubset#13 TRACE - Register rel#12:LogicalProject.NONE.[](input=RelSubset#11,EMPNO=$0,NAME=$1,DEPTNO=$2,GENDER=$3,CITY=$4,EMPID=$5,AGE=$6,SLACKER=$7,MANAGER=$8,JOINEDAT=$9) in rel#13:Subset#2.NONE.[] TRACE - Importance of [rel#11:Subset#1.NONE.[]] to its parent [rel#13:Subset#2.NONE.[]] is 0.0 (parent importance=0.0, child cost=1.0E30, parent cost=1.0E30) TRACE - Importance of [rel#11:Subset#1.NONE.[]] is 0.0 TRACE - Importance of [rel#13:Subset#2.NONE.[]] is 0.0 TRACE - OPTIMIZE Rule-match queued: rule [EnumerableProjectRule] rels [rel#12:LogicalProject.NONE.[](input=RelSubset#11,EMPNO=$0,NAME=$1,DEPTNO=$2,GENDER=$3,CITY=$4,EMPID=$5,AGE=$6,SLACKER=$7,MANAGER=$8,JOINEDAT=$9)] TRACE - OPTIMIZE Rule-match queued: rule [ProjectRemoveRule] rels [rel#12:LogicalProject.NONE.[](input=RelSubset#11,EMPNO=$0,NAME=$1,DEPTNO=$2,GENDER=$3,CITY=$4,EMPID=$5,AGE=$6,SLACKER=$7,MANAGER=$8,JOINEDAT=$9)] TRACE - OPTIMIZE Rule-match queued: rule [MaterializedViewJoinRule(Project-Filter)] rels [rel#12:LogicalProject.NONE.[](input=RelSubset#11,EMPNO=$0,NAME=$1,DEPTNO=$2,GENDER=$3,CITY=$4,EMPID=$5,AGE=$6,SLACKER=$7,MANAGER=$8,JOINEDAT=$9), rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John'))] TRACE - OPTIMIZE Rule-match queued: rule [ProjectFilterTransposeRule] rels [rel#12:LogicalProject.NONE.[](input=RelSubset#11,EMPNO=$0,NAME=$1,DEPTNO=$2,GENDER=$3,CITY=$4,EMPID=$5,AGE=$6,SLACKER=$7,MANAGER=$8,JOINEDAT=$9), rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John'))] TRACE - Importance of [rel#13:Subset#2.NONE.[]] is 1.0 TRACE - new LogicalFilter#14 TRACE - Register: rel#14 is equivalent to rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John')) TRACE - new LogicalProject#15 TRACE - Register: rel#15 is equivalent to rel#12:LogicalProject.NONE.[](input=RelSubset#11,EMPNO=$0,NAME=$1,DEPTNO=$2,GENDER=$3,CITY=$4,EMPID=$5,AGE=$6,SLACKER=$7,MANAGER=$8,JOINEDAT=$9) TRACE - new RelSubset#16 TRACE - new AbstractConverter#17 TRACE - Register rel#17:AbstractConverter.ENUMERABLE.[](input=RelSubset#13,convention=ENUMERABLE,sort=[]) in rel#16:Subset#2.ENUMERABLE.[] TRACE - Importance of [rel#13:Subset#2.NONE.[]] to its parent [rel#16:Subset#2.ENUMERABLE.[]] is 0.495 (parent importance=0.5, child cost=1.0E30, parent cost=1.0E30) TRACE - Importance of [rel#13:Subset#2.NONE.[]] is 0.495 TRACE - Importance of [rel#16:Subset#2.ENUMERABLE.[]] is 1.0 TRACE - OPTIMIZE Rule-match queued: rule [ExpandConversionRule] rels [rel#17:AbstractConverter.ENUMERABLE.[](input=RelSubset#13,convention=ENUMERABLE,sort=[])]
findBestExp 这里有 4 个 phase, 但是真的有用的只有一个 OPTIMIZE 阶段.
setInitialImportance() 从 root 开始, 将 root SubSet 设置 importance 为 1.0, 之后的其他 children SubSet 设置 importance 为 pow(0.9, n), n 为 children 在的层数. 经过这一步之后的信息, 可以看到 importance 分别为 1, 0.9, 0.81…:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Root: rel#16 :Subset#2. ENUMERABLE.[] Original rel: LogicalProject(EMPNO=[$0 ], NAME=[$1 ], DEPTNO=[$2 ], GENDER=[$3 ], CITY=[$4 ], EMPID=[$5 ], AGE=[$6 ], SLACKER=[$7 ], MANAGER=[$8 ], JOINEDAT=[$9 ]): rowcount = 15.0 , cumulative cost = {130.0 rows, 351.0 cpu, 0.0 io}, id = 7 LogicalFilter(condition=[=($1 , 'John' )]): rowcount = 15.0 , cumulative cost = {115.0 rows, 201.0 cpu, 0.0 io}, id = 5 LogicalTableScan(table=[[SALES, EMPS]]): rowcount = 100.0 , cumulative cost = {100.0 rows, 101.0 cpu, 0.0 io}, id = 0 Sets: Set#0 , type: RecordType(INTEGER EMPNO, VARCHAR NAME, INTEGER DEPTNO, VARCHAR GENDER, VARCHAR CITY, INTEGER EMPID, INTEGER AGE, BOOLEAN SLACKER, BOOLEAN MANAGER, DATE JOINEDAT) rel#9 :Subset#0. NONE.[], best=null , importance=0.7290000000000001 rel#0 :LogicalTableScan.NONE.[](table=[SALES, EMPS]), rowcount=100.0 , cumulative cost={inf} Set#1 , type: RecordType(INTEGER EMPNO, VARCHAR NAME, INTEGER DEPTNO, VARCHAR GENDER, VARCHAR CITY, INTEGER EMPID, INTEGER AGE, BOOLEAN SLACKER, BOOLEAN MANAGER, DATE JOINEDAT) rel#11 :Subset#1. NONE.[], best=null , importance=0.81 rel#10 :LogicalFilter.NONE.[](input=RelSubset#9 ,condition==($1 , 'John' )), rowcount=15.0 , cumulative cost={inf} Set#2 , type: RecordType(INTEGER EMPNO, VARCHAR NAME, INTEGER DEPTNO, VARCHAR GENDER, VARCHAR CITY, INTEGER EMPID, INTEGER AGE, BOOLEAN SLACKER, BOOLEAN MANAGER, DATE JOINEDAT) rel#13 :Subset#2. NONE.[], best=null , importance=0.9 rel#12 :LogicalProject.NONE.[](input=RelSubset#11 ,EMPNO=$0 ,NAME=$1 ,DEPTNO=$2 ,GENDER=$3 ,CITY=$4 ,EMPID=$5 ,AGE=$6 ,SLACKER=$7 ,MANAGER=$8 ,JOINEDAT=$9 ), rowcount=15.0 , cumulative cost={inf} rel#16 :Subset#2. ENUMERABLE.[], best=null , importance=1.0 rel#17 :AbstractConverter.ENUMERABLE.[](input=RelSubset#13 ,convention=ENUMERABLE,sort=[]), rowcount=15.0 , cumulative cost={inf}
由于现在还没有一个完整的物理执行计划, 所以整个计划的 best cost 还是 inf.
RuleQueue#popMatch 1 2 VolcanoRuleMatch match = ruleQueue.popMatch(phase); match.onMatch();
在初始 RuleQueue 里有 13 个 Rule Match.
1 2 3 4 5 6 7 8 9 10 11 12 13 rule [ExpandConversionRule] rels [rel#17:AbstractConverter.ENUMERABLE.[](input=RelSubset#13,convention=ENUMERABLE,sort=[])] rule [EnumerableProjectRule(in:NONE,out:ENUMERABLE)] rels [rel#12:LogicalProject.NONE.[](input=RelSubset#11,EMPNO=$0,NAME=$1,DEPTNO=$2,GENDER=$3,CITY=$4,EMPID=$5,AGE=$6,SLACKER=$7,MANAGER=$8,JOINEDAT=$9)]" rule [ProjectRemoveRule] rels [rel#12:LogicalProject.NONE.[](input=RelSubset#11,EMPNO=$0,NAME=$1,DEPTNO=$2,GENDER=$3,CITY=$4,EMPID=$5,AGE=$6,SLACKER=$7,MANAGER=$8,JOINEDAT=$9)]" rule [ProjectFilterTransposeRule] rels [rel#12:LogicalProject.NONE.[](input=RelSubset#11,EMPNO=$0,NAME=$1,DEPTNO=$2,GENDER=$3,CITY=$4,EMPID=$5,AGE=$6,SLACKER=$7,MANAGER=$8,JOINEDAT=$9), rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John'))]" rule [MaterializedViewJoinRule(Project-Filter)] rels [rel#12:LogicalProject.NONE.[](input=RelSubset#11,EMPNO=$0,NAME=$1,DEPTNO=$2,GENDER=$3,CITY=$4,EMPID=$5,AGE=$6,SLACKER=$7,MANAGER=$8,JOINEDAT=$9), rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John'))]" rule [ReduceExpressionsRule(Filter)] rels [rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John'))]" rule [MaterializedViewFilterScanRule] rels [rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John')), rel#0:LogicalTableScan.NONE.[](table=[SALES, EMPS])]" rule [FilterTableScanRule] rels [rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John')), rel#0:LogicalTableScan.NONE.[](table=[SALES, EMPS])]" rule [MaterializedViewJoinRule(Filter)] rels [rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John'))]" rule [EnumerableFilterRule(in:NONE,out:ENUMERABLE)] rels [rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John'))]" rule [TableScanRule] rels [rel#0:LogicalTableScan.NONE.[](table=[SALES, EMPS])]" rule [BindableTableScanRule] rels [rel#0:LogicalTableScan.NONE.[](table=[SALES, EMPS])]" rule [EnumerableTableScanRule(in:NONE,out:ENUMERABLE)] rels [rel#0:LogicalTableScan.NONE.[](table=[SALES, EMPS])]"
挑几个 rule 来举例子:
EnumerableProjectRule 可以看到在 convert 方法中生成了一个 EnumerableProject, 然后 transformTo 了过去.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 class EnumerableProjectRule extends ConverterRule EnumerableProjectRule() { super (LogicalProject.class, (Predicate<LogicalProject>) RelOptUtil::containsMultisetOrWindowedAgg, Convention.NONE, EnumerableConvention.INSTANCE, RelFactories.LOGICAL_BUILDER, "EnumerableProjectRule" ); } public void onMatch (RelOptRuleCall call) RelNode rel = call.rel(0 ); if (rel.getTraitSet().contains(inTrait)) { final RelNode converted = convert(rel); if (converted != null ) { call.transformTo(converted); } } } public RelNode convert (RelNode rel) final LogicalProject project = (LogicalProject) rel; return EnumerableProject.create( convert(project.getInput(), project.getInput().getTraitSet() .replace(EnumerableConvention.INSTANCE)), project.getProjects(), project.getRowType()); } public static RelNode convert (RelNode rel, RelTraitSet toTraits) RelOptPlanner planner = rel.getCluster().getPlanner(); RelTraitSet outTraits = rel.getTraitSet(); for (int i = 0 ; i < toTraits.size(); i++) { RelTrait toTrait = toTraits.getTrait(i); if (toTrait != null ) { outTraits = outTraits.replace(i, toTrait); } } if (rel.getTraitSet().matches(outTraits)) { return rel; } return planner.changeTraits(rel, outTraits); } }
在方法 transformTo 中可以看到 register 了这个新生成的物理算子(EnumerableProject): volcanoPlanner.ensureRegistered(rel, rels[0], this) , 这次第二个参数 equivRel 不是 null 了, 而是 rels[0](LogicalProject). 在 VolcanoPlanner#register 中会拿到 equivRel 对应的 RelSet, 再走下去就又是上面的 registerImpl, 只不过这时候会有一个 set 传入.
这样就把新生成的这个物理算子注册到了原来的 RelSet 树上, 完成了 transform 的过程.
由于有新的算子生成(EnumerableProject), fireRule 会匹配一条新的规则到 ruleQueue 中.
1 OPTIMIZE Rule-match queued: rule [ProjectRemoveRule] rels [rel#19:EnumerableProject.ENUMERABLE.[](input= ...]
Before
After
ProjectRemoveRule 因为查询是 select * , 所以可以直接取出这个 projection.
1 2 3 4 5 6 7 public void onMatch (RelOptRuleCall call) Project project = call.rel(0 ); RelNode stripped = project.getInput(); ... RelNode child = call.getPlanner().register(stripped, project); call.transformTo(child); }
可以看到这个规则直接就把 project 节点的 child 注册到当前 RelSet, 也就是说直接消除了这个 projection, 故这个新的 plan 的 cost 一定会比原来低.
merge : RelSet merge(RelSet set, RelSet set2): 合并两个 RelSet.
RelSet#mergeWith(VolcanoPlanner planner, RelSet otherSet)
1 2 3 4 5 6 7 8 9 10 11 12 13 for (RelSubset otherSubset : otherSet.subsets) { planner.ruleQueue.subsetImportances.remove(otherSubset); RelSubset subset = getOrCreateSubset( otherSubset.getCluster(), otherSubset.getTraitSet()); if (otherSubset.bestCost.isLt(subset.bestCost)) { changedSubsets.put(subset, otherSubset.best); } for (RelNode otherRel : otherSubset.getRels()) { planner.reregister(this , otherRel); } }
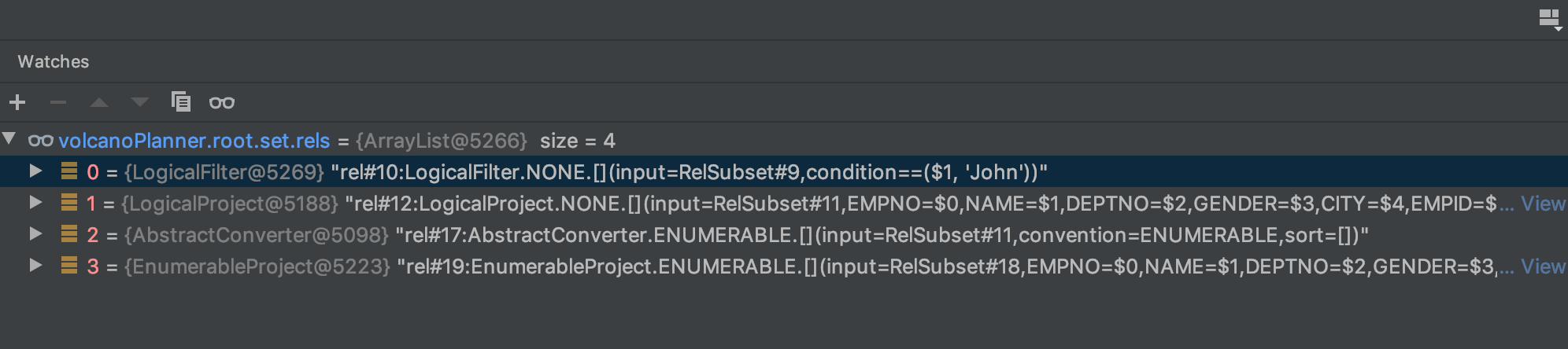
经过这个 rule 之后, 来看看 root 的 relset 的前后对比, 可以看到在这一层多了一个 logical filter.
before
after
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Root: rel#18:Subset#1.ENUMERABLE.[] Original rel: LogicalProject(EMPNO=[$0], NAME=[$1], DEPTNO=[$2], GENDER=[$3], CITY=[$4], EMPID=[$5], AGE=[$6], SLACKER=[$7], MANAGER=[$8], JOINEDAT=[$9]): rowcount = 15.0, cumulative cost = {130.0 rows, 351.0 cpu, 0.0 io}, id = 7 LogicalFilter(condition=[=($1, 'John')]): rowcount = 15.0, cumulative cost = {115.0 rows, 201.0 cpu, 0.0 io}, id = 5 LogicalTableScan(table=[[SALES, EMPS]]): rowcount = 100.0, cumulative cost = {100.0 rows, 101.0 cpu, 0.0 io}, id = 0 Sets: Set#0, type: RecordType(INTEGER EMPNO, VARCHAR NAME, INTEGER DEPTNO, VARCHAR GENDER, VARCHAR CITY, INTEGER EMPID, INTEGER AGE, BOOLEAN SLACKER, BOOLEAN MANAGER, DATE JOINEDAT) rel#9:Subset#0.NONE.[], best=null, importance=0.7290000000000001 rel#0:LogicalTableScan.NONE.[](table=[SALES, EMPS]), rowcount=100.0, cumulative cost={inf} Set#1, type: RecordType(INTEGER EMPNO, VARCHAR NAME, INTEGER DEPTNO, VARCHAR GENDER, VARCHAR CITY, INTEGER EMPID, INTEGER AGE, BOOLEAN SLACKER, BOOLEAN MANAGER, DATE JOINEDAT) rel#11:Subset#1.NONE.[], best=null, importance=0.81 rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John')), rowcount=15.0, cumulative cost={inf} rel#12:LogicalProject.NONE.[](input=RelSubset#11,EMPNO=$0,NAME=$1,DEPTNO=$2,GENDER=$3,CITY=$4,EMPID=$5,AGE=$6,SLACKER=$7,MANAGER=$8,JOINEDAT=$9), rowcount=15.0, cumulative cost={inf} rel#18:Subset#1.ENUMERABLE.[], best=null, importance=0.405 rel#17:AbstractConverter.ENUMERABLE.[](input=RelSubset#11,convention=ENUMERABLE,sort=[]), rowcount=15.0, cumulative cost={inf} rel#19:EnumerableProject.ENUMERABLE.[](input=RelSubset#18,EMPNO=$0,NAME=$1,DEPTNO=$2,GENDER=$3,CITY=$4,EMPID=$5,AGE=$6,SLACKER=$7,MANAGER=$8,JOINEDAT=$9), rowcount=15.0, cumulative cost={inf}
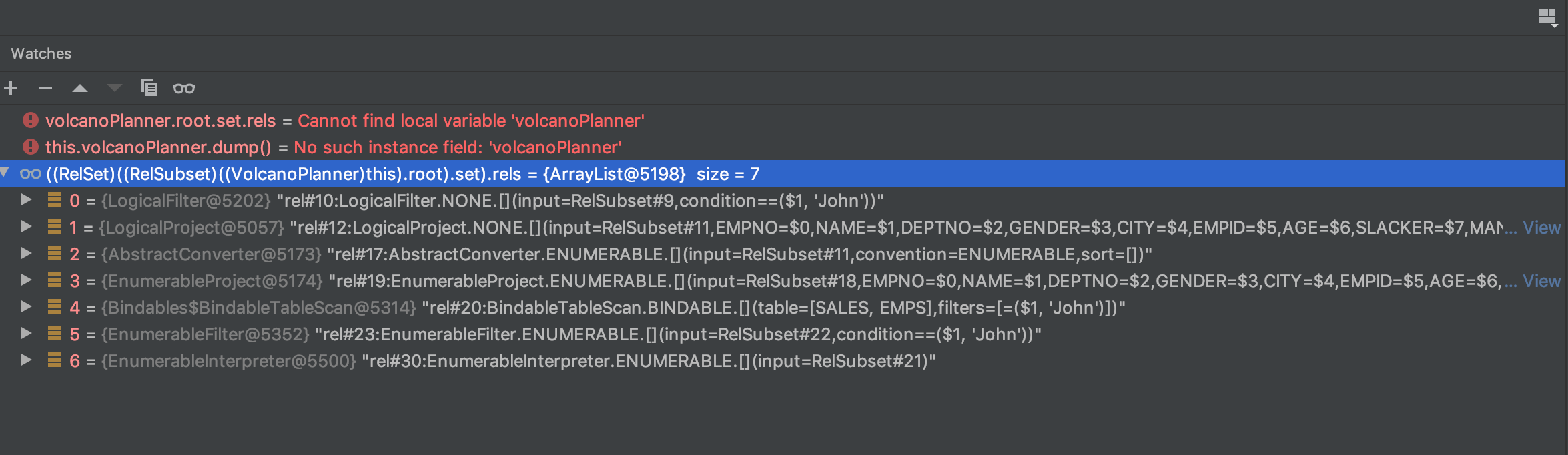
经过所有规则之后: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 Root: rel#18:Subset#1.ENUMERABLE.[] Original rel: LogicalProject(EMPNO=[$0], NAME=[$1], DEPTNO=[$2], GENDER=[$3], CITY=[$4], EMPID=[$5], AGE=[$6], SLACKER=[$7], MANAGER=[$8], JOINEDAT=[$9]): rowcount = 15.0, cumulative cost = {130.0 rows, 351.0 cpu, 0.0 io}, id = 7 LogicalFilter(condition=[=($1, 'John')]): rowcount = 15.0, cumulative cost = {115.0 rows, 201.0 cpu, 0.0 io}, id = 5 LogicalTableScan(table=[[SALES, EMPS]]): rowcount = 100.0, cumulative cost = {100.0 rows, 101.0 cpu, 0.0 io}, id = 0 Sets: Set#0, type: RecordType(INTEGER EMPNO, VARCHAR NAME, INTEGER DEPTNO, VARCHAR GENDER, VARCHAR CITY, INTEGER EMPID, INTEGER AGE, BOOLEAN SLACKER, BOOLEAN MANAGER, DATE JOINEDAT) rel#9:Subset#0.NONE.[], best=null, importance=0.81 rel#0:LogicalTableScan.NONE.[](table=[SALES, EMPS]), rowcount=100.0, cumulative cost={inf} rel#22:Subset#0.ENUMERABLE.[], best=rel#27, importance=0.9 rel#27:EnumerableInterpreter.ENUMERABLE.[](input=RelSubset#26), rowcount=100.0, cumulative cost={51.0 rows, 51.01 cpu, 0.0 io} rel#26:Subset#0.BINDABLE.[], best=rel#25, importance=0.81 rel#25:BindableTableScan.BINDABLE.[](table=[SALES, EMPS]), rowcount=100.0, cumulative cost={1.0 rows, 1.01 cpu, 0.0 io} Set#1, type: RecordType(INTEGER EMPNO, VARCHAR NAME, INTEGER DEPTNO, VARCHAR GENDER, VARCHAR CITY, INTEGER EMPID, INTEGER AGE, BOOLEAN SLACKER, BOOLEAN MANAGER, DATE JOINEDAT) rel#11:Subset#1.NONE.[], best=null, importance=0.9 rel#10:LogicalFilter.NONE.[](input=RelSubset#9,condition==($1, 'John')), rowcount=15.0, cumulative cost={inf} rel#12:LogicalProject.NONE.[](input=RelSubset#11,EMPNO=$0,NAME=$1,DEPTNO=$2,GENDER=$3,CITY=$4,EMPID=$5,AGE=$6,SLACKER=$7,MANAGER=$8,JOINEDAT=$9), rowcount=15.0, cumulative cost={inf} rel#18:Subset#1.ENUMERABLE.[], best=rel#30, importance=1.0 rel#17:AbstractConverter.ENUMERABLE.[](input=RelSubset#11,convention=ENUMERABLE,sort=[]), rowcount=15.0, cumulative cost={inf} rel#19:EnumerableProject.ENUMERABLE.[](input=RelSubset#18,EMPNO=$0,NAME=$1,DEPTNO=$2,GENDER=$3,CITY=$4,EMPID=$5,AGE=$6,SLACKER=$7,MANAGER=$8,JOINEDAT=$9), rowcount=100.0, cumulative cost={150.5 rows, 1050.505 cpu, 0.0 io} rel#23:EnumerableFilter.ENUMERABLE.[](input=RelSubset#22,condition==($1, 'John')), rowcount=15.0, cumulative cost={66.0 rows, 151.01 cpu, 0.0 io} rel#30:EnumerableInterpreter.ENUMERABLE.[](input=RelSubset#21), rowcount=100.0, cumulative cost={50.5 rows, 50.505 cpu, 0.0 io} rel#21:Subset#1.BINDABLE.[], best=rel#20, importance=0.9 rel#20:BindableTableScan.BINDABLE.[](table=[SALES, EMPS],filters=[=($1, 'John')]), rowcount=100.0, cumulative cost={0.5 rows, 0.505 cpu, 0.0 io}
buildCheapestPlan 从 root 开始一路选subset 中的 best, 就得到了一颗最优的树:
1 2 EnumerableInterpreter BindableTableScan(table = [[SALES, EMPS]], filters= [[= ($1 , 'John' )]])
优化策略
第一次找到可执行计划的计划(cost 不为 inf), 其对应的 Cost 暂时记为 BestCost
制定下一次优化要达到的目标为 BestCost*0.9,再根据当前的迭代次数计算 giveUpTick,这个值代表的意思是:如果迭代次数超过这个值还没有达到优化目标,那么将会放弃迭代
如果 RuleQueue 中 RuleMatch 为空,那么也会退出迭代
在每次迭代时都会从 RuleQueue 中选择一个 RuleMatch,策略是选择一个最高 importance 的 RuleMatch
最后根据 best plan,构建其对应的 RelNode
总结 优点:
为异构数据源提供了原生支持 (conversion 机制)
volcano 的优化规则顺序不需要人工保证, 因为每次新生成一个节点, 会去执行 fireRule, 找到所有这个节点感兴趣的 rule 放到 RuleQueue 中, 当同时带来缺点 1.
缺点:
CBO 是个伪命题, 执行的框架模型很不错, 但是如何准确预估 cost 是难点(Filter/Join/Agg)
更好的方式是做成 runtime 的, 一边执行, 一边根据执行的 stats 调整查询计划的形式(ae/runtime filter).
重复应用规则, 有一些(很多)规则会同时被 logical/physical nodes 触发, 比如 ProjectRemoveRule 接受 Project.class, 而 Project 是逻辑/物理 Project 的 基类, 很多规则仅在逻辑执行计划上 apply 就可以了. 在社区的讨论中, 去掉了这种 case, planning 的时间提升 30% (CALCITE-2970);
Calcite 的 Volcano Planner 没有任何剪枝, 举例来说, 当计算一个计划到某个节点的 cost 已经比之前的 best 都高了, 则可以剪去这一枝;
本质上还是一个单机的优化引擎, 没有考虑分布式的优化(对比 Spark , Calcite 可以理解为无物理优化)
默认优化流程里根本没有加入 RelDistribution 的考虑, 也没有提供配置
Distribution 也不是分布式的, 举例 calcite 的 HASH_DISTRIBUTED 值考虑了 Key, hash 的 func/num 都没有记录
Aggregate 只有一种, 对比 Spark 有多种策略(planAggregateWithoutDistinct/planAggregateWithOneDistinct/planStreamingAggregation)
有多种 join, 但是 join 策略比较弱, 没有考虑数据量(对比 Spark 的 JoinSelection), 也不支持 hint
引入 AbstractConverter 来做 Spark ensureRequirement 类似的事情, 但是做的方式比较别扭, AbstractConverter 是一个执行计划中的节点, 会触发一个特定的规则 ExpandConversionRule 来保证 Distribution/Sort/Convertion, 邮件列表中讨论到这种方式污染了规则的 search space(polluting the search space), 导致了3-9 倍不必要的规则触发(对比 spark 是递归处理 root-child, calcite 每次只处理父子两个节点, 不递归). 由于它潜在的性能问题(CALCITE-2970 ), AbstractConverter 在 Calcite 代码中是默认关闭的, 详见社区讨论: Volcano’s problem with trait propagation: current state and future;
复杂度高, 不利于调试问题.
1 2 3 4 5 6 7 8 9 SELECT u.id AS user_id, u.name AS user_name, j.company AS user_company, u.age AS user_age FROM users uJOIN jobs j ON u.id= j.idWHERE u.age > 30 AND j.id> 10 ORDER BY user_id"
共形成了 31 个 group(relset), 1000 个节点(开启了3 种 RelTraitDef)
Ref [1]. https://zhuanlan.zhihu.com/p/58801070
[2]. https://zhuanlan.zhihu.com/p/60223655