作者: 陶加涛/高官涛/网上各种资料
基本概念
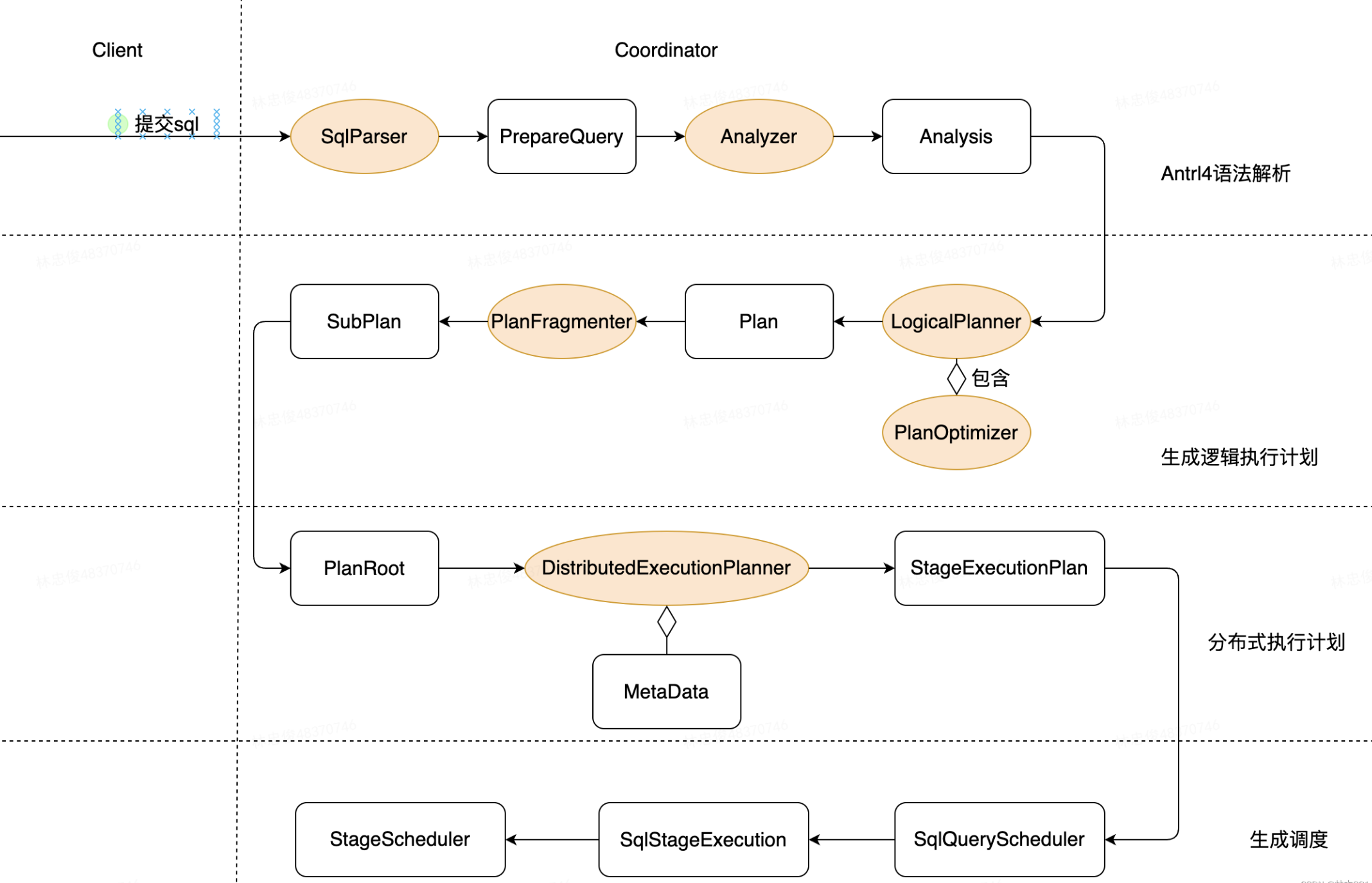
Stage: 逻辑概念, 指可以在一个节点上执行的一部分执行计划, 对应一个
PlanFragment, 一般按照 exchange 来划分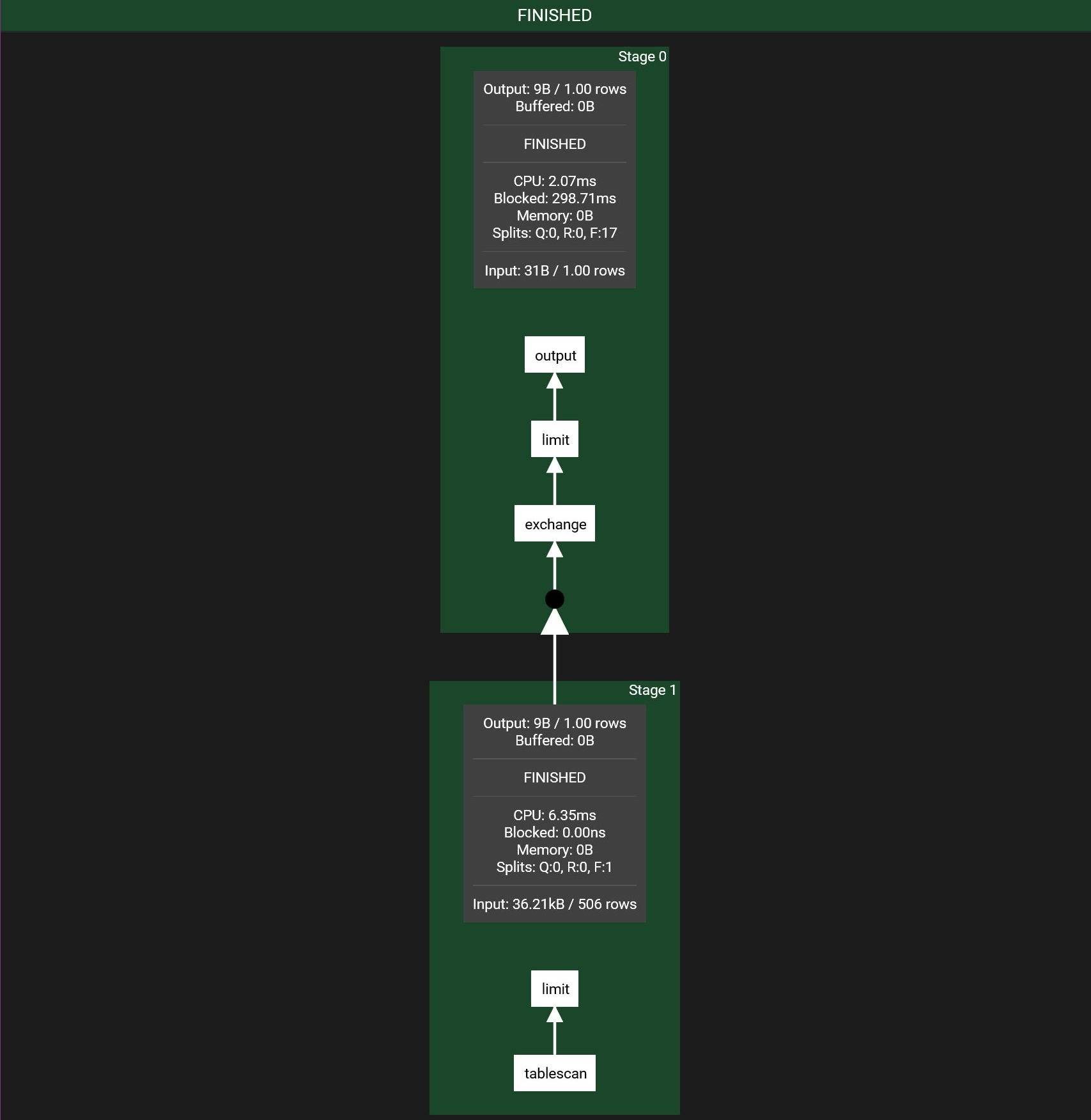
Task: Stage 的实例, Stage只是定义了执行计划怎么划分, 接下来会被调度到各个机器上去执行, 每一个Stage 的实例就称为Task; 一个 Stage 分为一系列的 Task , 负责管理 Task 和封装建模, Stage 实际运行的是Task; Task 运行在各个具体节点上.
- 一个Presto里的Worker只会运行一个Stage的一个实例. 当然它会跑多个Task, 但它们一般来说是属于不同的Stage的
- ui 上每个Stage需要的Task数可以认为Worker数
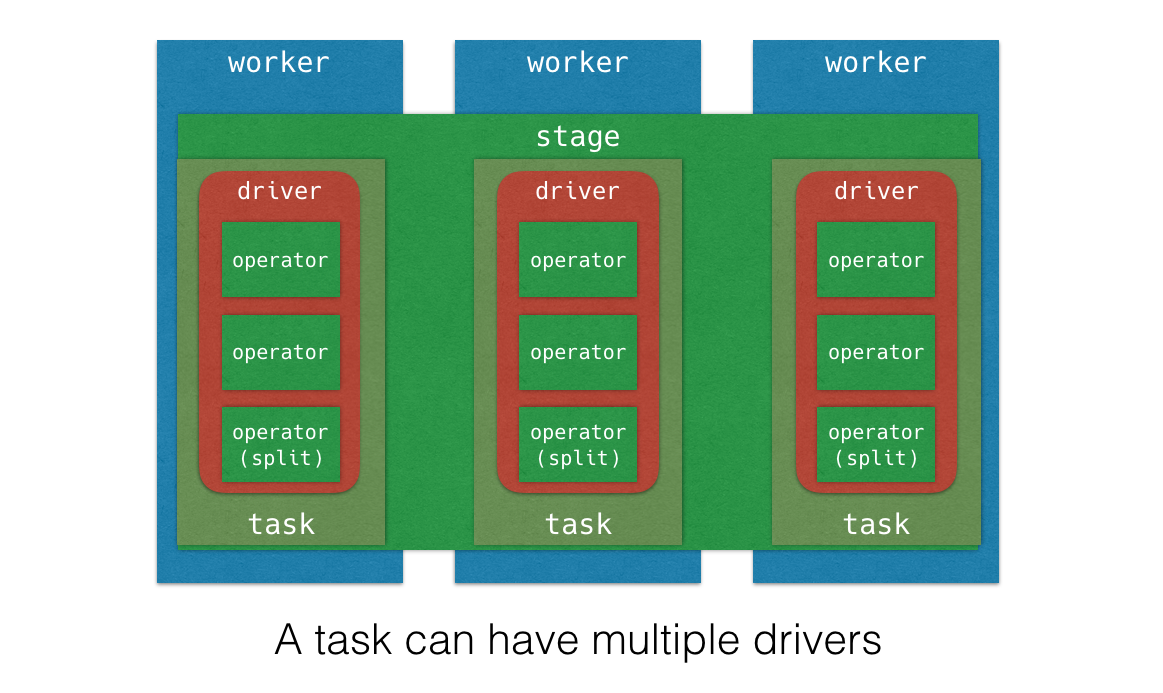
Pipeline: 虚拟概念
Task 执行 stage(PlanFragment) 的逻辑, 就是执行一组 operator, 执行 operator 的最佳并行度可能是不同的, 比如说做Tablescan的并发可以很大, 但做Final Aggregation(如Sort)的并发度只能是一;
所以一个 stage 会被切为若干 pipeline, 每个 Pipeline 由一组 Operator 组成, 这些 Operator 被设置同样的并行度. Pipeline 之间会通过 LocalExchangeOperator 来传递数据.
driver 的数量就是 pipeline 的并行度
Driver: Pipeline其实是一个虚拟的概念, 它的实例就叫Driver; Task 被分解成一个或者多个 Driver, 并行执行多个 Driver 的方式来实现 Task 的并行执行. Driver 是作用于一个 Split 的一系列 Operator 的集合. 一个 Driver 处理一个 Split, 产生输出由 Task 收集并传递给下游的 Stage 中的一个 Task. 一个 Driver 拥有一个输入和输出.
- Pipeline 的实例是 Driver, 可以说Pipeline就是DriverFactory, 用来create Driver
- Driver里不再有并行度, 每个Driver都是单线程的.
Operator: Operator 表示对一个 Split 的一种操作. 比如过滤、转换等. 一个 Operator 一次读取一个 Split 的数据, 将 Operator 所表示的计算、操作作用于 Split 的数据上, 产生输出. 每个 Operator 会以 Page 为最小处理单位分别读取输入数据和产生输出数据. Operator 每次只读取一个 Page,输出产生一个 Page.
Split: 分片, 和 MR 的 split 概念相似, 包含 page
Page: 处理的最小数据单元. 一个 Page 对象包括多个 Block 对象, 而每个 Block 对象是一个字节数组, 存储一个字段的若干行. 多个 Block 的横切的一行表示真实的一行数据. 一个 Page 最大 1MB, 最多 16 * 1024 行数据
基础总结
- Stage 对应一个 PlanFragment
- Task 是 Stage的实例
- 每个 Stage会被拆分为若干 Pipeline
- Driver 是 Pipeline的实例, 并发度的最小单位
- Split 是 Table的一个分片, 在Hive中可以对应HDFS文件的一个分片
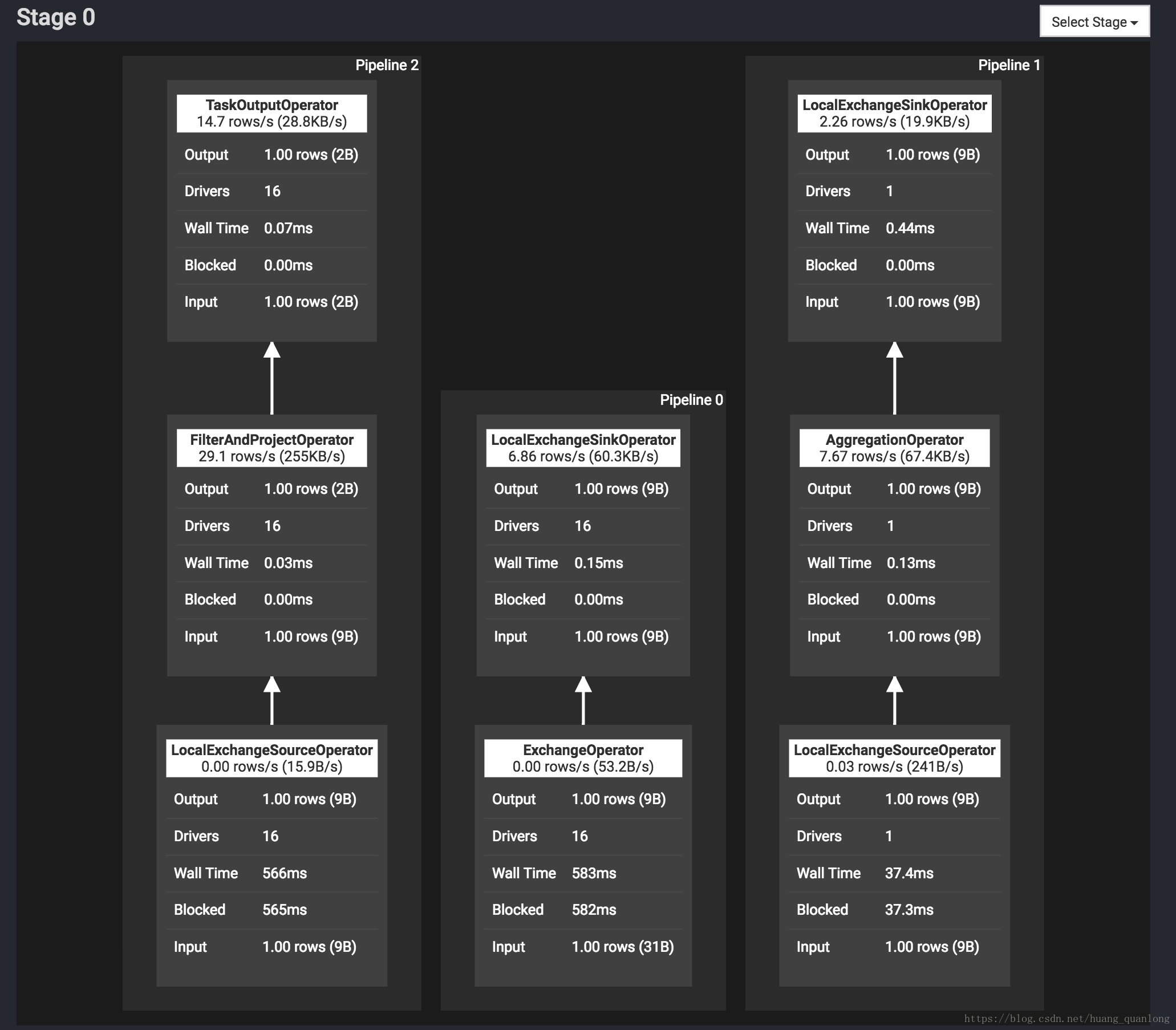
Coordinator 端 Scheduler
资源组介绍
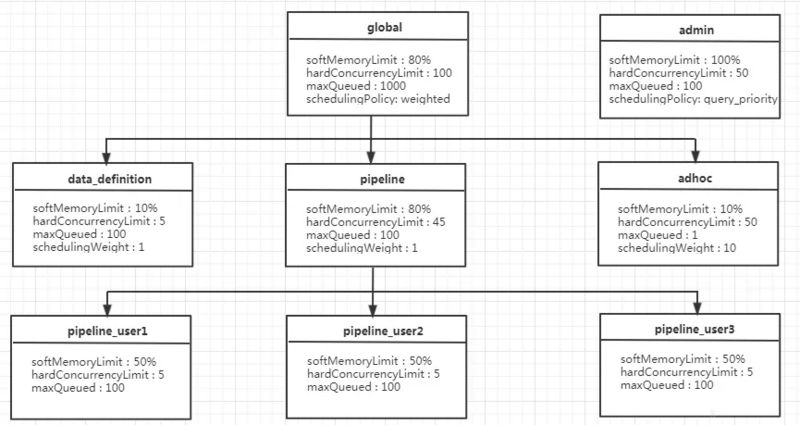
- 类比 yarn 的队列, 满足多租户下资源调度
- 资源组之间形成树形结构
- query 可以绑定到任意节点
属性
name(required): 资源组名称, 支持模板adhoc-$USERmaxQueued(required): 最大排队数, 超过会拒绝hardConcurrencyLimit(required): 最大运行查询数softMemoryLimit(required): 资源组最大内存使用量softCpuLimit(optional): 到达该阈值后, 该资源组内占据最大CPU资源的查询的CPU资源会被减少(惩罚措施)hardCpuLimit(optional): 资源组最大 CPU 使用量, 当达到此阈值后, 新任务进入排队schedulingPolicy(optional): 调度策略fair:FIFO, 默认, 一般线上用
weighted_fair: 采取这种策略的每一个资源组会配置一个属性schedulingWeight, 每个子资源组会计算一个比值:
当前子资源组查询数量/schedulingWeight, 比值越小的子资源组越先得到资源, 相对于其共享并发性最低的子组被选择以开始下一个查询
weighted: 以query_priority为权重, 按比例随机挑选, 随机选的时候取值范围按权重等比例划分, 比如权重是a=1, b=3, 随机数小于 0.25 取a, 否则取b
query_priority: 严格根据其优先级进行选择
perQueryLimits: 限制每条 query, 超过会被 kill
- executionTimeLimit
- totalMemoryLimit
- cpuTimeLimit
Query 调度
为 Query 绑定资源组 (DispatchManager#createQueryInternal), 无资源组的 Query 将被拒绝执行
根据 client 传来的一系列信息选择(
StaticSelector#match)- user (by client)
- source (by client)
- clientTags (by client)
- queryType: (by parser): 可以对不同的查询类型queryType, 比如
EXPLAIN、INSERT、SELECT和DATA_DEFINITION等类型, 匹配到不同的资源组, 分配不同的资源, 来执行查询 - resourceEstimates: (by client)
- executionTime
- cpuTime
- peakMemory
匹配器
每一个大括号代表一个匹配资源组的选择器selector, 这里定义了 5 个选择器匹配各自资源组
要全部满足当前selector全部条件, 才可放进当前队列执行. 比如amy用户使用jdbc方式提交的查询, 如果没有配置clientTags, 是不能够分配到资源组
global.adhoc.bi-${toolname}.${USER}对应的资源当一个查询能同时满足两个seletor时, 会匹配第一个满足要求的seletor
1 | "selectors": [ |
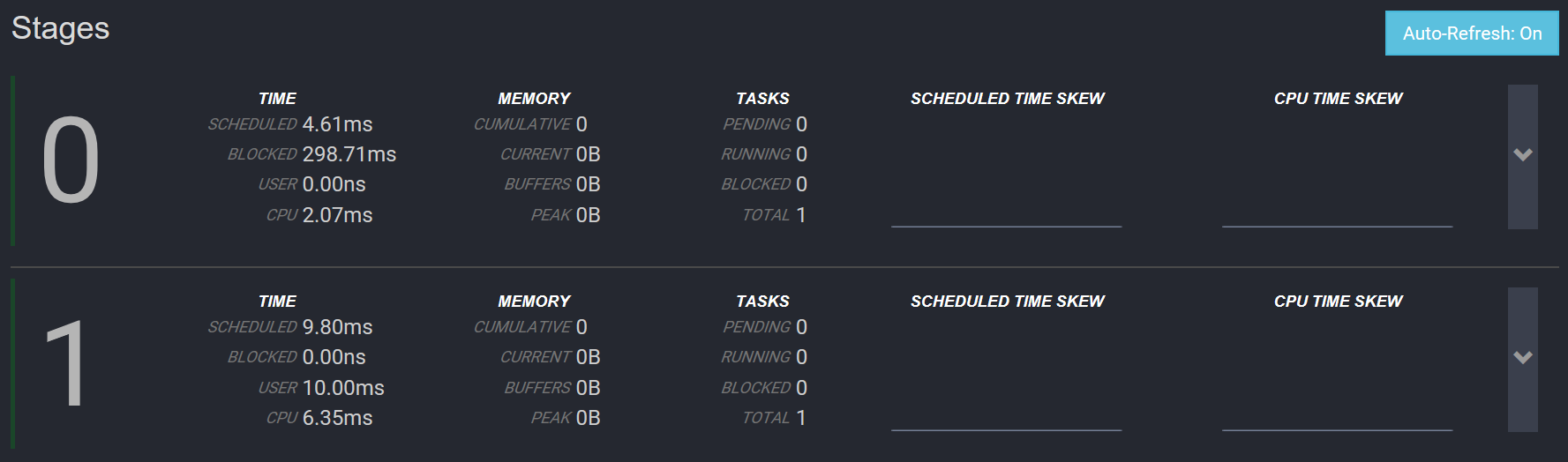
Stage 调度
| 类型 | 描述 |
|---|---|
| Source | 一般是TableScanNode、ProjectNode、FilterNode, 一般是最下游的取数的Stage |
| Fixed | 一般在Source之后, 将Source阶段获取的数据分散到多个节点上处理, 类似于Map端reduce操作, 包括局部聚合、局部Join、局部数据写入 |
| Single | 一般在Fixed之后, 只在一台机器上进行, 汇总所有的结果、做最终聚合、全局排序, 并将结果传输给Coordinator |
| Coordinator_only | 只在Coordinator上 |
主流程
其主要逻辑实现在SqlQueryScheduler.schedule方法中, 其主要执行流程如下:
获取所有处于执行就绪状态(
isReadyForExecution)的stage加入到待调度队列中;遍历待调度队列中的stage并应用运行时CBO优化其执行计划;
为每个stage添加相应的执行策略(all-at-once/phased);
- All-at-once: 就是一次调度所有 stage 以最小化 Wall Clock Time, 数据一旦可用就会被处理; 虽然是一次性调度, 但各个 stage 之间是有序的, 从叶子节点开始自底向上的去调度, 适用于延迟敏感的场景
- Phased: 分阶段调度, 核心就是构建一个 DAG 图, 有依赖关系的子任务在图上加边; 典型操作如hash-join, 需要先build好, 再启动probe端, 在构建哈希表之前, 不会对左侧的流调度任务进行调度. 比较节约内存, 适用于批处理场景
遍历待调度队列(
SqlStageExecution)中的stage并进行调度执行一个 stage;调度
SqlStageExecution时, 根据StageExecutionAndScheduler绑定的StageScheduler执行StageScheduler#scheduler(), 得到ScheduleResult- 下面会具体介绍
StageScheduler#scheduler()
- 下面会具体介绍
stage 调度器每完成一次调度, 都会产生对应的调度结果
ScheduleResult,StageLinkage会根据ScheduleResult的结果和状态来跟新sourceTask的信息. 如果此stage包含remoteSourceNode, 则要根据allTask和sourceTask来为task创建依赖的remoteSplit. 如果存在remoteSplit则会更新RemoteTask(远程update)启动
RemoteTask的start()方法. 开始轮询获取task的状态, 不停的更新SqlStageExecution所有有关task的变量. 直到所有task完成HttpRemoteTask#sendUpdate会最终调用http 发送,httpClient.executeAsync(request, responseHandler);
不断循环直至查询执行完成, 并在某个stage执行完成时更新其状态以及下游stage的输入数据位置信息, 从而可以让下游stage也转变成就绪状态可以被调度执行;
executionAndScheduler.getStageLinkage().processScheduleResults根据当前stage的结果, 设置父stage的shuffle追踪地址(用来进行stage间的exchange数据)
调度策略基本概念
Source stage: 首先为stage的每一个split source来分配node, 然后将split运行起来, 即schedulerSplit(本质是创建Task, task运行在split上)
- coordinator会尝试从 connector 获取对应TableScanNode的splits, split包含isRemotelyAccessible属性. 当remotelyAccessible=false时, 该 split 只能被下发至addresses包含的Presto Worker上;而当remotelyAccessible=true时, 该split可能被调度至集群内的任意一个Presto Worker上. 当该stage的split为第一次被调度至Presto Worker上时, coordinator就会往该Presto Worker下发Task.
Remote stage: stage的 split 都是remote split. 即根据NodePartitionMap中维护的本stage可以执行的node列表, 来调度task(scheduleTask)
Coordinator 会从Presto Worker中选择min(hashPartitionCount, aliveWokers)个worker, 每个worker下发一个task
RemoteSplit本质就是一个用来标记数据位置的URL, Driver在执行到ExchangeOperator算子时, 通过该URL去拉取数据进行运算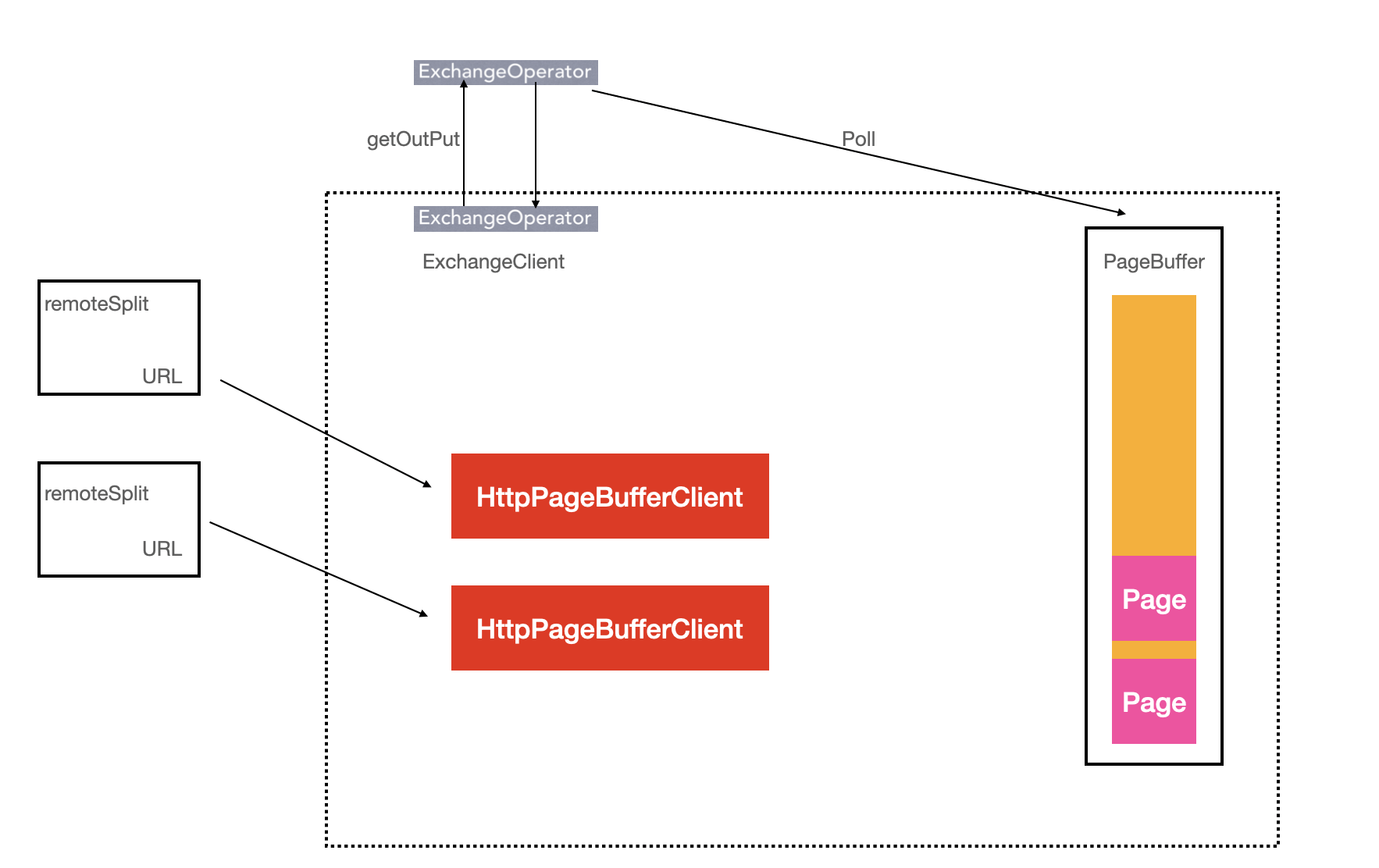
Split的计算, Split的下发都有可能阻塞, 所以采用异步调用的方式
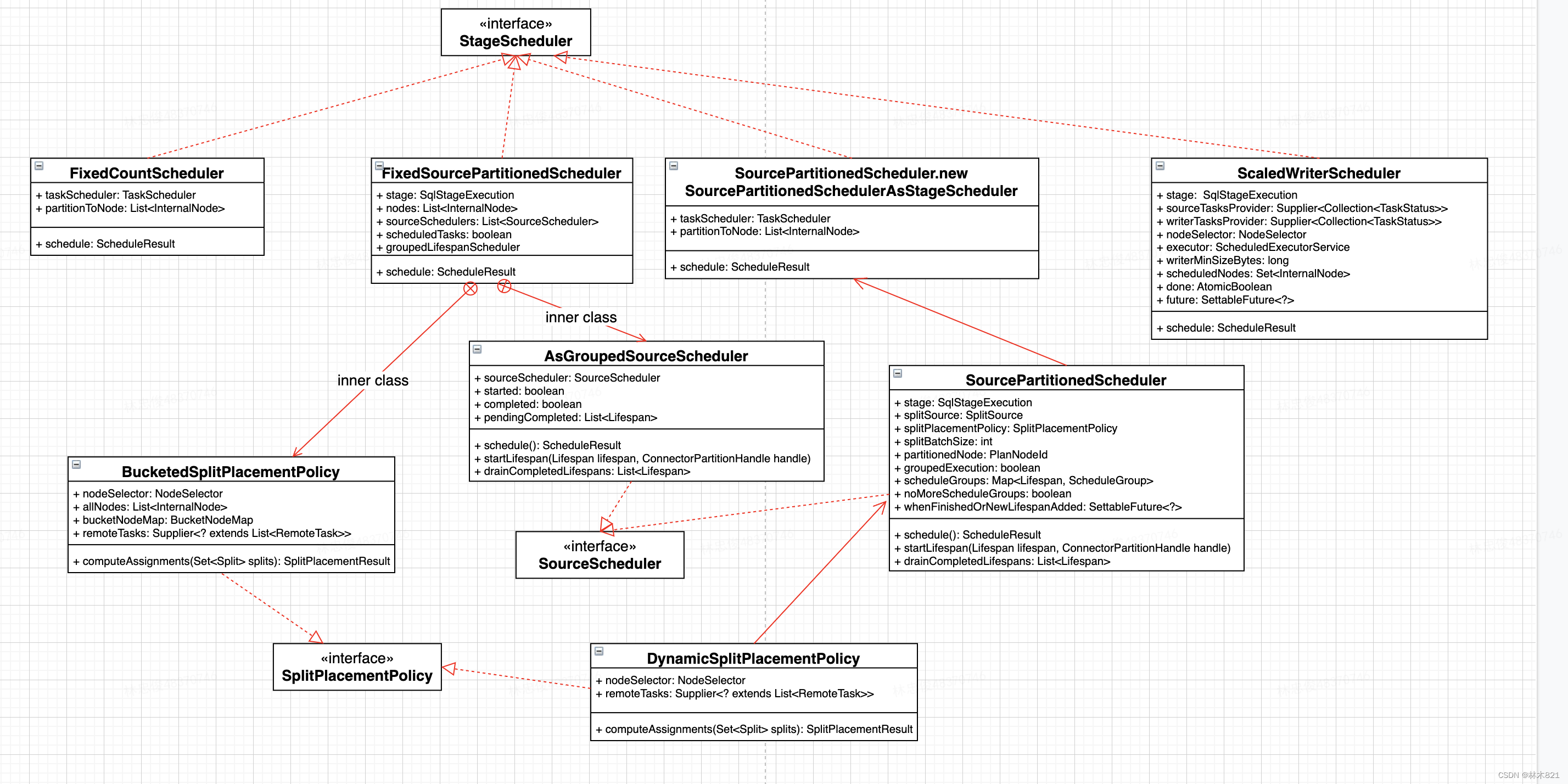
调度器
在SqlQueryScheduler#schedule 方法中会为不同的stage创建不同的调度器(SectionExecutionFactory#createStageScheduler)
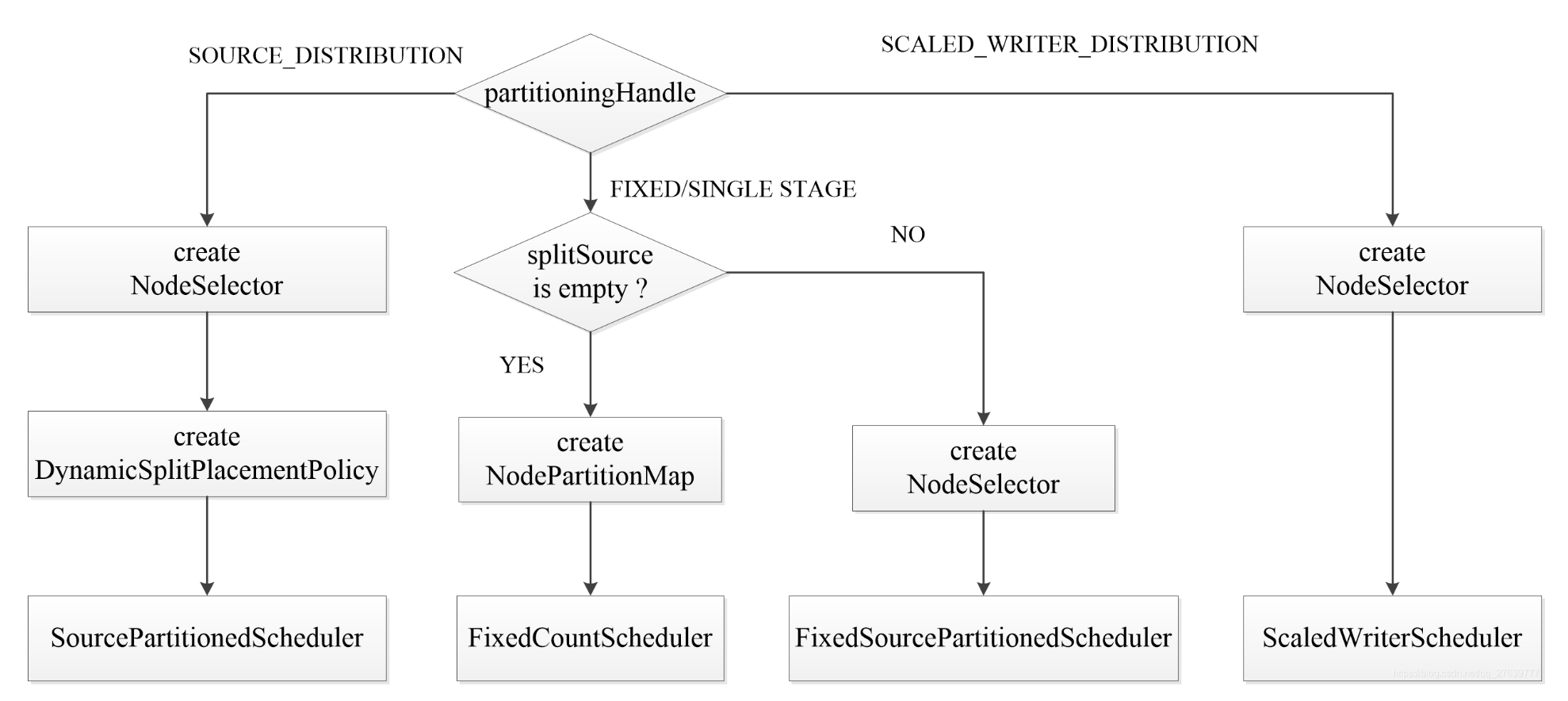
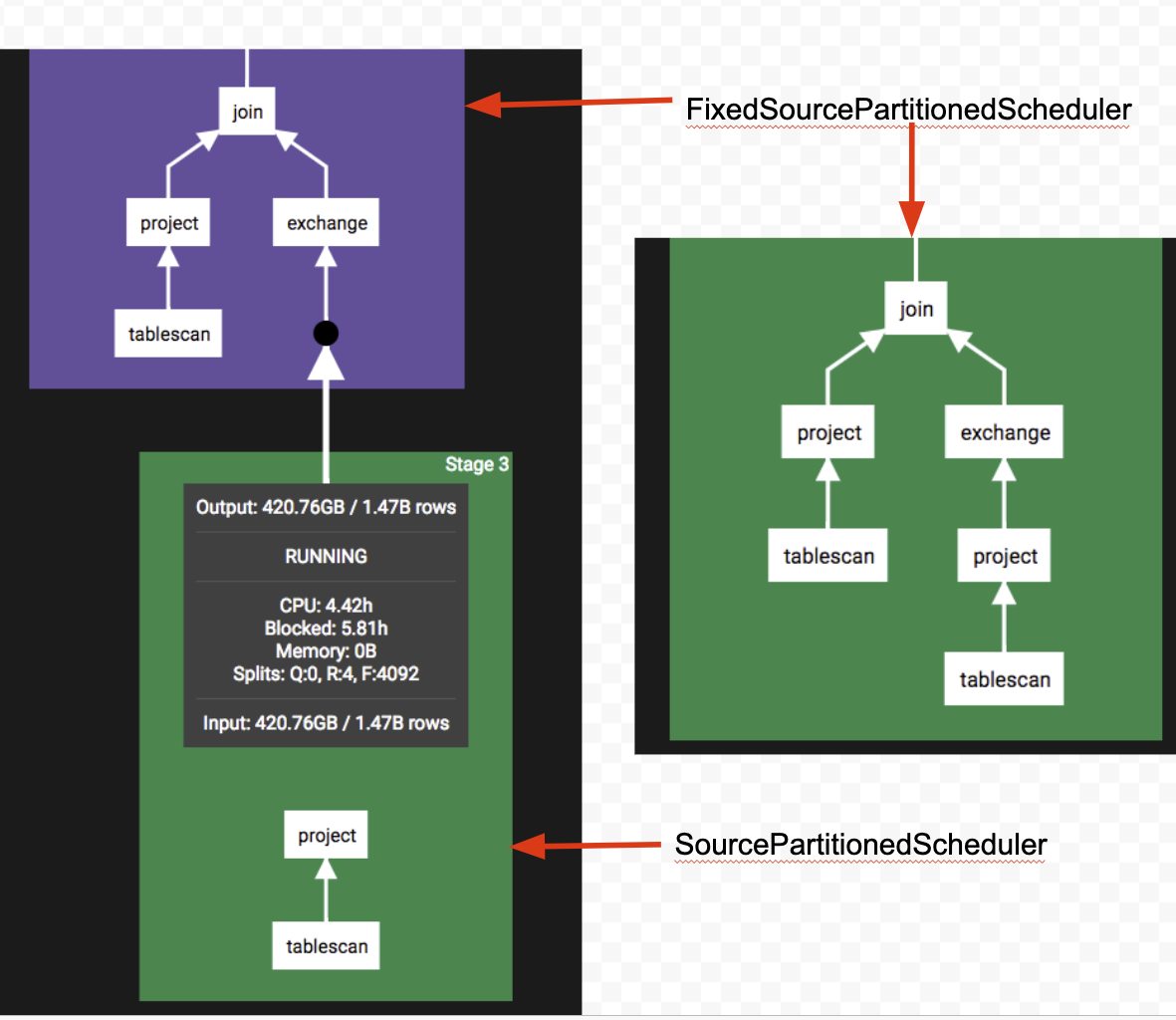
- SourcePartitionedScheduler:叶子节点, 只读一张表
- ScaledWriterScheduler:写数据节点
- FixedCountScheduler:非叶子节点
- FixedSourcePartionedScheduler:叶子节点, 读多张表
ScheduleResult
ScheduleResult schedule(); 函数签名的返回
包含:
- Set
newTasks; - ListenableFuture<?> blocked;
- Optional
blockedReason; - boolean finished;
- int splitsScheduled;
有两种阻塞原因:
WAITING_FOR_SOURCE: 拿 splits 阻塞(SplitSource#getNextBatch)SPLIT_QUEUES_FULL: node 忙碌, 一些 splits还没有分配(位置在NodeSelector#computeAssignments)
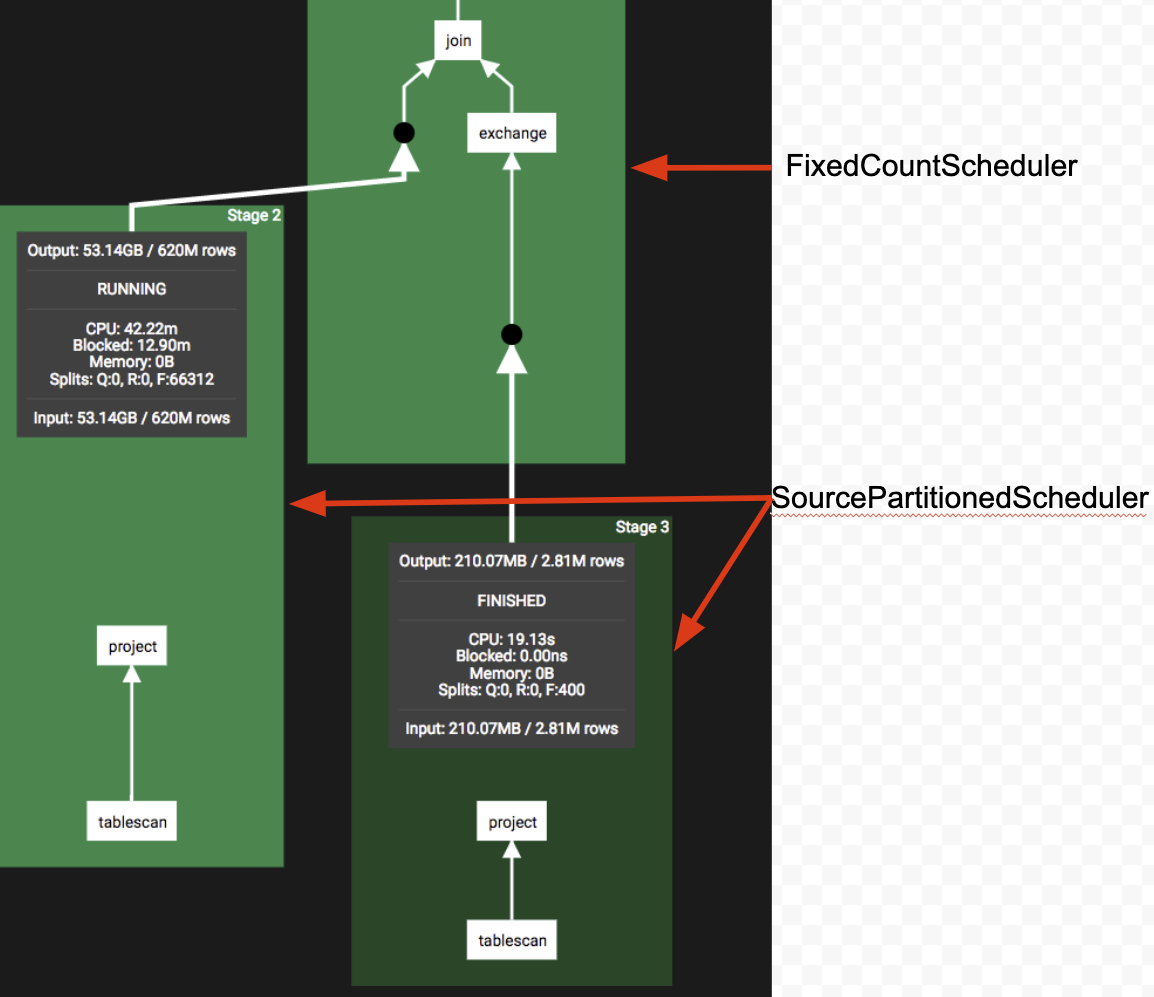
Source Stage调度(SourcePartitionedScheduler)
Source stage, 读取分布式数据源的调度器实现, 一般为叶子节点
凡是包含 TableScanNode 的执行计划都需要使用 SourcePartitionedScheduler 来完成 SplitSource 中每个 split 到执行节点的分配(assignSplits过程), 如果表是 unbucketed, 在生成执行计划时会把TableScanNode拆分成一个独立的stage(至多加上FilterNode)
assignSplits返回Set<RemoteTask>assignSplits会调用scheduleSplitsscheduleSplits会调用scheduleTaskscheduleTask会调用 `createRemoteTask``remote 调用
HttpRemoteTask#start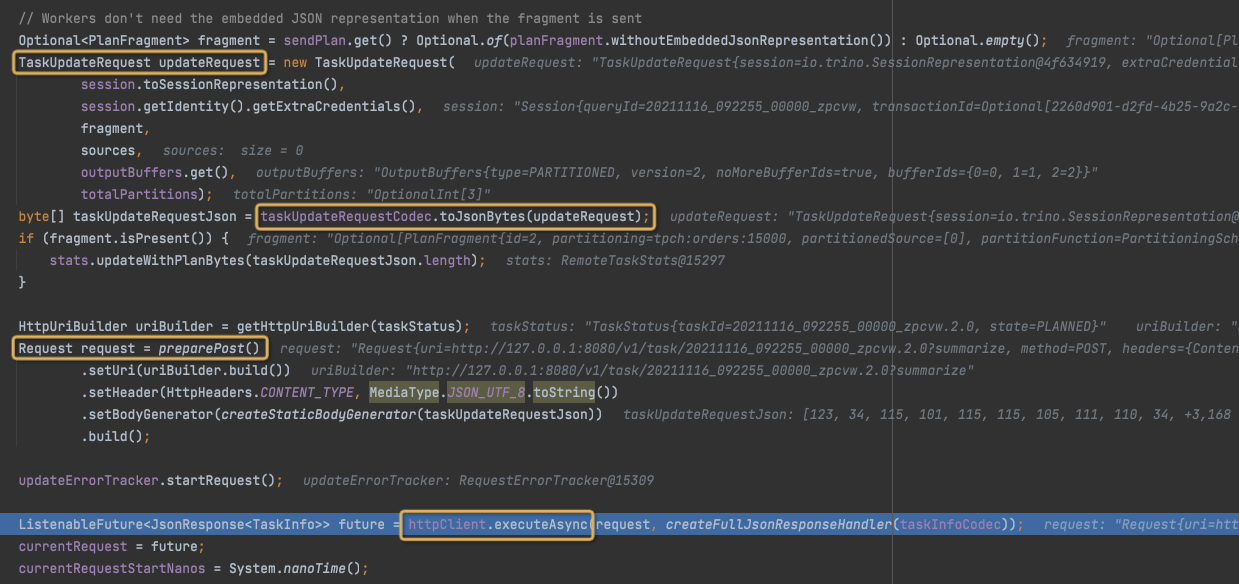
有一个额外的操作即对数据Split进行调度, 给需要处理的split分配执行节点, 通过
splitPlacementPolicy.computeAssignments方法为split分配节点有两种策略
DynamicSplitPlacementPolicy:(底层数据表是bucketed表), 在生成执行时会使用NodePartitionManager生成split和node的映射关系, 在具体调度时使用映射管理来为split分配nodeBucketedSplitPlacementPolicy:(底层数据表是unbucketed表), 在具体调度执行前为split分配node, 用于FixedSourcePartionedScheduler
节点分配split策略
SimpleNodeSelector#computeAssignments
- 将所有活跃的工作节点作为候选节点;
- 如果分片的节点选择策略是
HARD_AFFINITY, 即分片只能选择特定节点, 则根据分片要求更新候选节点列表, 如果选择不到特定节点, 会把所有节点都加入黑名单; - 如果分片的节点选择策略不是
HARD_AFFINITY, 则根据节点的网络拓扑, 从候选节点中选择和分片偏好节点网络路径最匹配的节点列表来更新候选节点列表; - 将活跃节点随机打散(
ResettableRandomizedIterator), 使用chooseLeastBusyNode方法从更新后的候选节点列表中选择最合适的节点来分配分片;
如何判断节点是否繁忙
chooseLeastBusyNode
- 剔除 dead node
- 优先选择 prefered node(当node不忙碌的时候)
- 选择最空的节点
1 | Optional<InternalNodeInfo> chooseLeastBusyNode(SplitWeight splitWeight, List<InternalNode> candidateNodes, ToLongFunction<InternalNode> splitWeightProvider, OptionalInt preferredNodeCount, long maxSplitsWeight, NodeAssignmentStats assignmentStats) |
Write stage 调度(ScaledWriterScheduler)
按需分配, 首次分配一个节点 (随机选择
nodeSelector.selectRandomNodes(count, scheduledNodes);)此后轮询检查上游状态, 当同时满足以下条件时, 新分配一个节点(随机选择)
- 半数以上的上游Task的
OutputBuffer写满 - 当前已分配节点平均写数据量已超过阈值 (writer_min_size, 默认 32MB)
- 半数以上的上游Task的
bucket 表不走这个 scheduler, 走的是
FixedCountScheduler; 只有对写入数据无分区约束的 Fragment 会使用这个 scheduler;通过 write_min_size 约束防止小文件过多
Exchange stage 调度(FixedCountScheduler)
最简单的scheduler, 所有 split source 都是 remote 的, 典型场景 join/agg on unbucket table
一次性创建 N 个 Task 分配到对应节点上
根节点, N = 1
非根节点, N = min(100, workerCount)
创建任务:
SqlStageExecution#scheduleTask()RemoteTask task = remoteTaskFactory.createRemoteTask(...)分配节点:
SystemPartitioningHandle.getPartitionToNode- 随机选择:
NodeSelector.selectRandomNodes, 对于小集群 (<100), 基本上要分布到所有节点 所以不如随机选(存疑) COORDINATOR: 选择当前节点Single:随机地从所有存活节点列表中选择一个节点Fixed: 随机选择参数hash_partition_count和max_tasks_per_stage两者的小值数量的节点min(getHashPartitionCount, getMaxTasksPerStage),getHashPartitionCount默认 100
1
2
3
4
5
6if (partitioning == SystemPartitioning.COORDINATOR_ONLY)
nodes = ImmutableList.of(nodeSelector.selectCurrentNode());
else if (partitioning == SystemPartitioning.SINGLE)
nodes = nodeSelector.selectRandomNodes(1);
else if (partitioning == SystemPartitioning.FIXED)
nodes = nodeSelector.selectRandomNodes(min(getHashPartitionCount(session), getMaxTasksPerStage(session)));- 随机选择:
输入包含本地数据源(FixedSourcePartionedScheduler)
- 说明: 用于 Bucket Join, splitSource 中至少有一个是source split, 可以包含remote split且source split对应的table是bucket表.
- 逻辑是先类似
FixedCountScheduler去创建 task, 然后再调用SourcePartitionedScheduler的逻辑(BucketedSplitPlacementPolicy: 根据Split和NodePartitionMap中的bucketToNode信息来为Split来分配Node) - 有多个源表, 每个源表对应一个
SourcePartitionedScheduler, 帮忙 schedule splits - 按照顺序 (右表->左表) 触发
SourcePartitionedScheduler的调度 - 场景:
- Colocated join(i.e. join two bucketed tables).
- Bucketed table join unbucketed table. 这种场景下 remote exchange 会被加到 unbucketed table side, 来适应一样的 bucketing.
StageLinkage
- 存储了每个Stage的调度策略和调度链
- 根据当前stage的结果, 设置父stage的shuffle追踪地址(用来进行stage间的exchange数据)
OutputBuffer: 缓存当前Task生成的数据, 供下游Task消费.- 在进行Stage调度时会调用
StageLinkage的processScheduleResults函数
1 | // Add an exchange location to the parent stage for each new task |
| PartitioningHandle | OutputBufferManager |
|---|---|
| FIXED_BROADCAST_DISTRIBUTION | BroadcastOutputBufferManager |
| SCALED_WRITER_DISTRIBUTION | ScaledOutputBufferManager |
| 其他 | PartitionedOutputBufferManager |
总结
如果目标节点上不存在Task, 则调用
SqlStageExecution#scheduleTask, 如果目标节点存在Task, 则往SqlStageExecution@tasks中的目标Task中添加split从整体上来说, Split分配节点的方式基本为随机选择的策略, 在此基础上尽量保证每个节点处理的Split相对平均
Split的拆分计算是异步的, 在开始调度的时Split的计算进度未知, 故使用一个While循环来一直判断Split是否计算完成, Split的下发是否计算完成等. 调度完成的条件是每个Stage被调度完成(Split计算完成, Split下发完成, Task发送到Woker完成)
Split的计算, Split的下发都有可能阻塞, 所以采用异步调用的方式
每次while执行时, 如果只获取到部分Split, 也会进行Split下发和Task的生成发送到woker, 在后续再读取到Split时会根据Split和Node的信息来选择是新建还是更新Task, 一旦处于
no_more_split时则说明Stage对应的Split已经完全获取完成对于非Source类型的Stage, 不存在获取Split和下发Split的过程, 其读取的Split为下游Stage的产出, 会使用StageLinkage来维护, 调度时只需要根据节点负载信息来调度task即可
前面
RemoteTask后,通过 REST 请求将task任务下放到对应的worker上去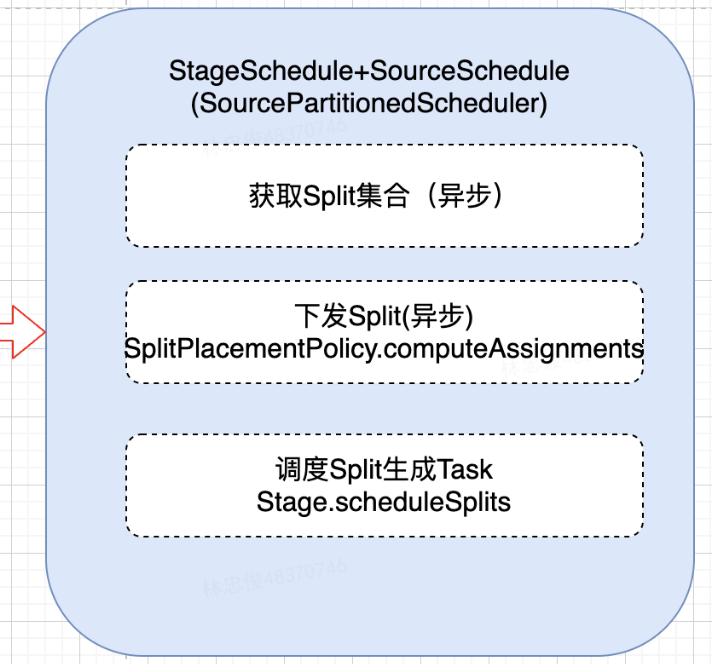
StageScheduler
总体流程
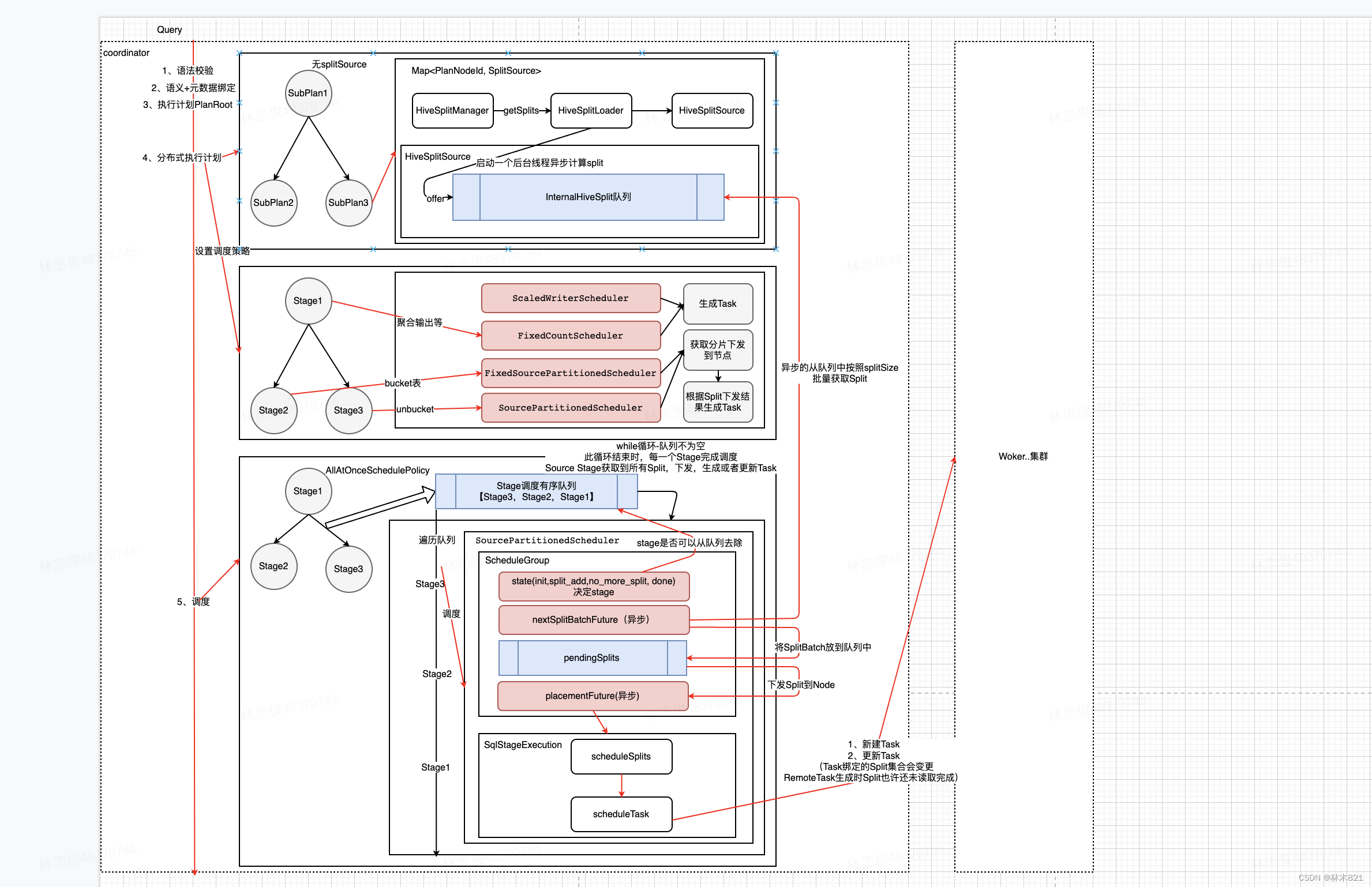
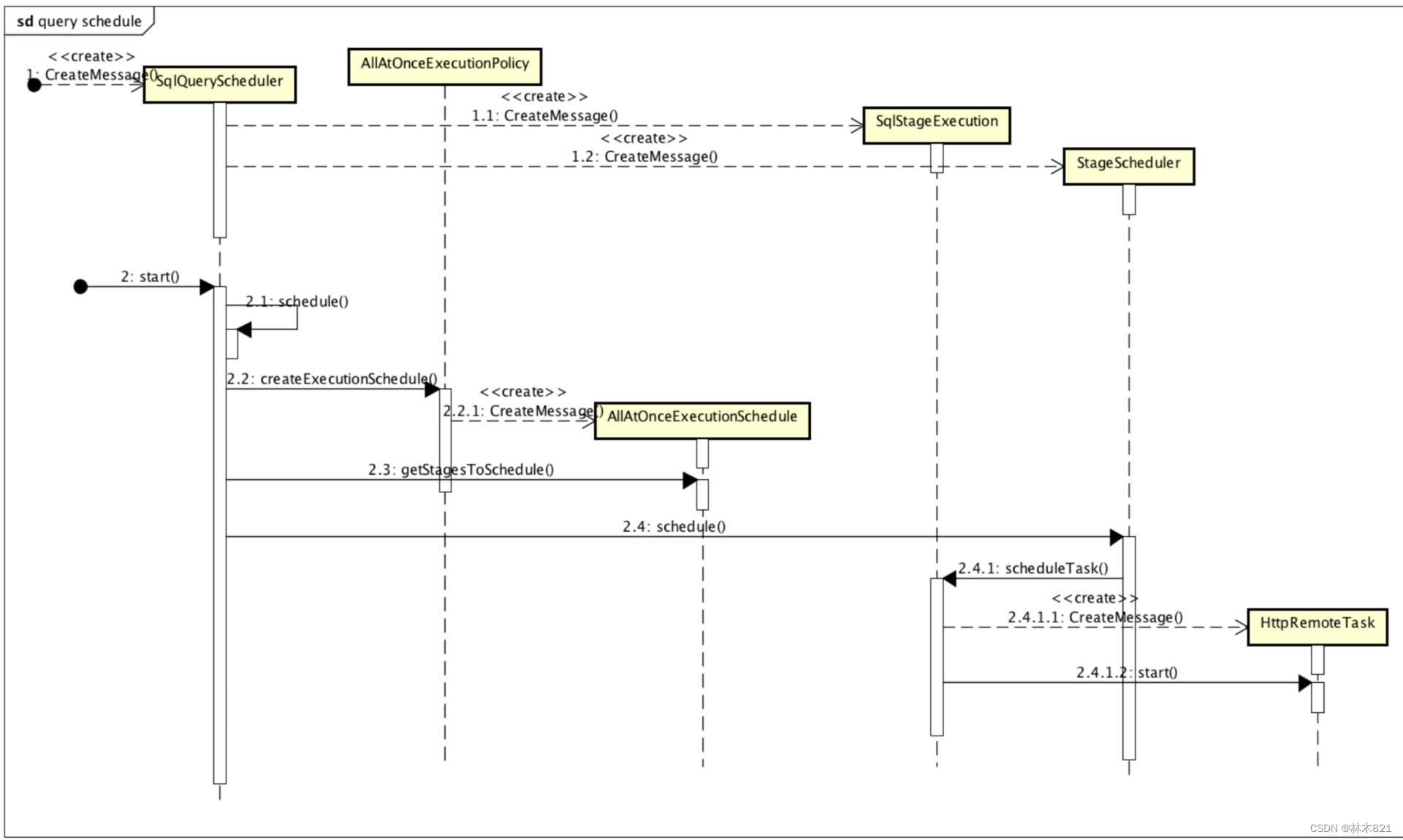
HTTP API 介绍
Stage服务接口
处理Stage相关的请求, 只有一个功能, 即取消或者结束一个指定的Stage
/v1/stage/{stageId}– DELETE 提前结束一个Stage
Task服务接口
与Task相关的请求, 如Task的创建, 更新, 状态查询和结果查询等.
/v1/task/{taskId}– POST 创建一个新的Task或者更新Task状态, 如果存在taskID对应的Task, 就而根据taskUpdateRequest中的内容更新Task, 否则创建一个新的Task/v1/task/{taskId}– GET 获取Task相关的信息/v1/task/{taskId}– DELETE 删除或提前结束对应的Task/v1/task/{taskId}/results/{outputId}/{token}– GET 用于获得TaskId指定的Task生成的用于输出给下游Task(由outputId标识)的数据/v1/task/{taskId}/results/{outputId}/{token}– DELETE 用于删除TaskId指定的Task生成的用于输出给下游Task(由outputId标识)的数据
Worker 端 Scheduler
Driver 回顾
最小调度单元
Driver 的数量就是 pipeline 的并行度, Driver 是作用于一个 Split 的一系列 Operator 的集合
Driver里不再有并行度, 每个Driver都是单线程的.
每个 Driver 拥有一个输入和输出.
Driver 调度
基本概念
- presto 会给执行任务分配一个时间分片, 将时间分片轮流分给任务, 以最小化lantency以及避免饥饿的情况.
- 多层级的优先队列(MultilevelSplitQueue), 通过累计任务运行时间来平衡不同时长之间竞争关系, 通过累计运行时间的方式让队列不断升级, 让同样代价的任务尽可能的只跟同级别的任务进行竞争.
MultilevelSplitQueue:内置了一个分层的优先队列, 按照level维护了调度的时间和优先级分数等待统计- 每一个level, 都有一个目标的总调度时间, 然后这样的level, 即这个level对应的已经使用的调度时间占总调度时间的比例最小
TaskExecutor: 单个实例内的只有一个, 接受外接的任务调度请求和任务状态管理, 持有工作线程资源以及维护一些必要的统计信息, 内部会维持一个MultilevelSplitQueue, 该队列维持了一个等待调度的splitPrioritizedSplitRunner: 实现类似操作系统的分片调度的能力, 在进行调度的时候每次只会调度这个接口的 processor 一个时间分片, 然后重新寻找一个合适的task用于下一个分片的执行- 使用一个
TaskPriorityTracker来统一搜集类型运行时间和管理优先级调度策略.
具体流程
入队调度
TaskExecutor负责Split的轮流执行, 由于Split的数量不可预知且大部分情况下都非常大, 因此我们不可能为每一个Split启动对应的线程, 唯一的方法就是采用操作系统的设计, 创建有限的固定数量的线程, 然后不同的SplitRunner按照时间片使用这些线程
- Worker节点将小任务封装成一个
PrioritizedSplitRunner对象,放入pending split 优先级队列中 - Worker节点启动一定数目的线程进行计算(
TaskExecutor#runnerThreads),线程数``task.shard.max-threads= Runtime.getRuntime().availableProcessors() * 2`; - 每个空闲线程从队列中取出PrioritizedSplitRunner对象执行,每隔1秒,判断任务是否执行完成,如果完成,从allSplits队列中删除,如果没有,则放回pendingSplits队列
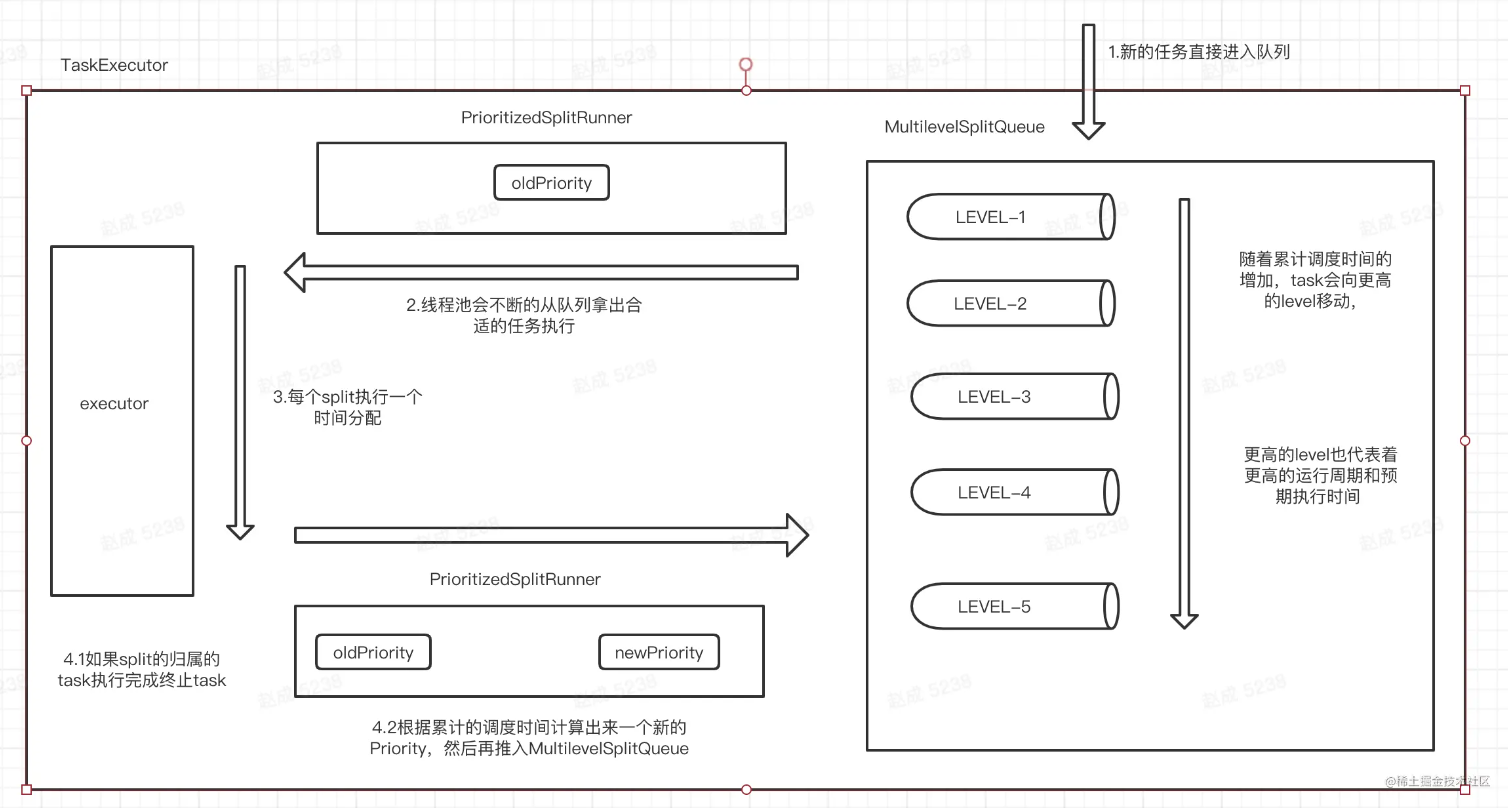
- finished splits: 意思是已经完全执行完毕的splits, 即这个split对应的driver的状态已经是finished的
- waiting splits: 等待分配时间片的split
- blocked splist: splits没有执行完, 但是时间片已经到了
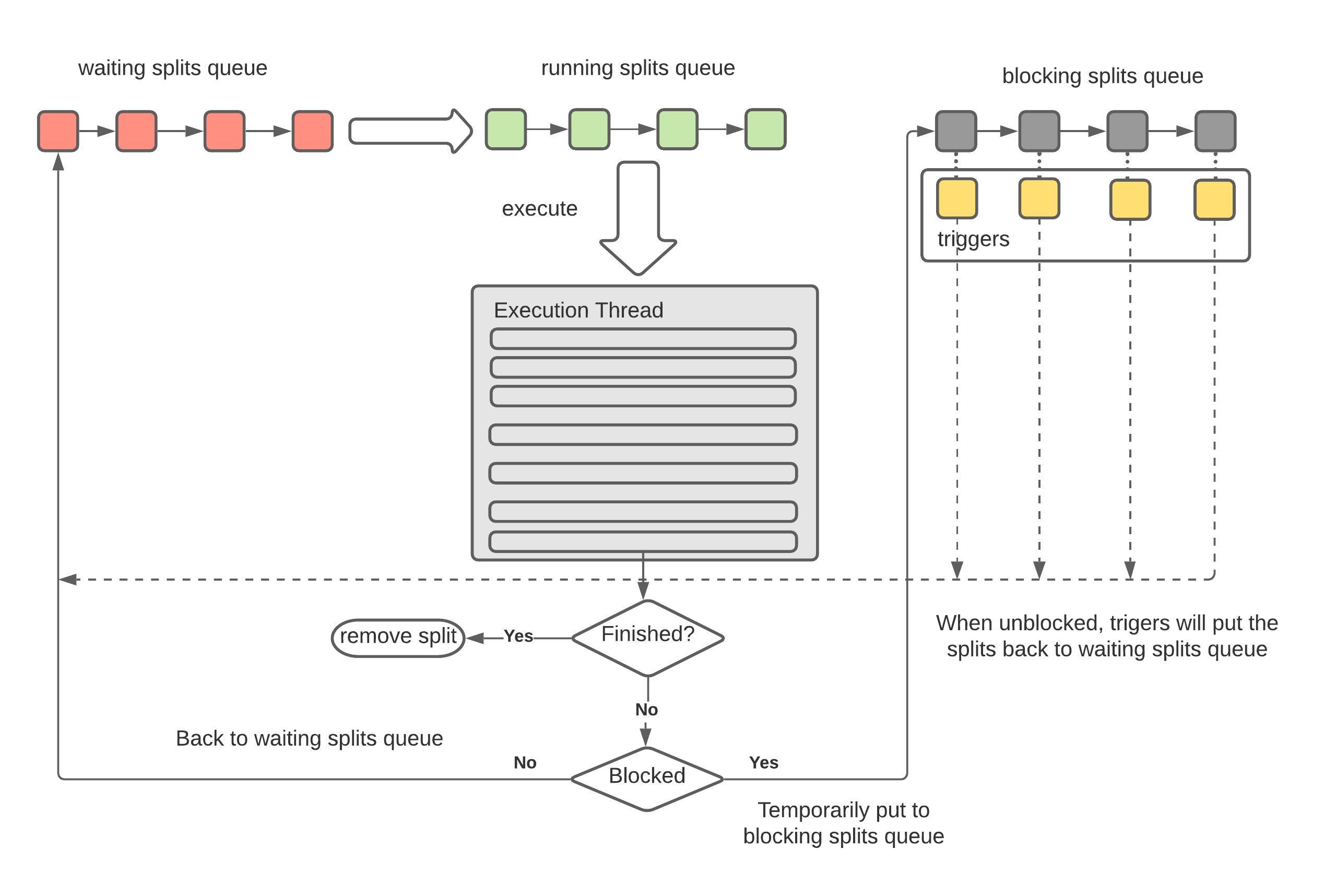
- 定时检查, 如果 OutputBuffers 使用率低于 0.5 (下游消费较快, 需要提高生产速度), 并发度+1
SplitConcurrencyController#TARGET_UTILIZATION- 主要逻辑可以参考
PrioritizedSplitRunner
- 主要逻辑可以参考
时间片调度
- Worker 线程池: CPU * 2
- 对于每个线程, 重复以下过程 (模拟时间片轮转):
- 从 MSQ 中取出一个可运行的 Driver
- 循环执行 Driver#process 方法直到超过 1s
- 如果 process 阻塞, 让出时间片, 通过回调再加入队列
- 如果 process 没有完成, 放回队列上述过程经过的时间, 记为 driver 的调度时间 (scheduledTime, 每一轮是 quantaTime)
- 耗时算子主动检查:DriverYieldSignal#isSet
模拟协程(setWithDelay)
driverContext.getYieldSignal().setWithDelay(maxRuntime, driverContext.getYieldExecutor());
1 | public synchronized void setWithDelay(long maxRunNanos, ScheduledExecutorService executor) |
当前这个Driver获取了1s的时间片, 就设置一个delay为一秒的Future, 即这个Future会在1s以后被调度, 把一个yield变量设置为true, 然后各个不同的Operator去自行check这个标记位, 以ScanFilterAndProjectOperator为例:
1 | private Page processPageSource() |
Presto Exchange
上面写的比较零碎, 这里总结下
Presto在数据进行shuffle的时候是Pull模式, 在两端负责分发和交换数据的类分别是ExchangClient和OutputBuffer.
Source Stage把数据从Connector中拉取出来, 会先把数据放在OutputBuffer中, 等待上游把数据请求过去, 而上游请求数据的类就是ExchangeClient
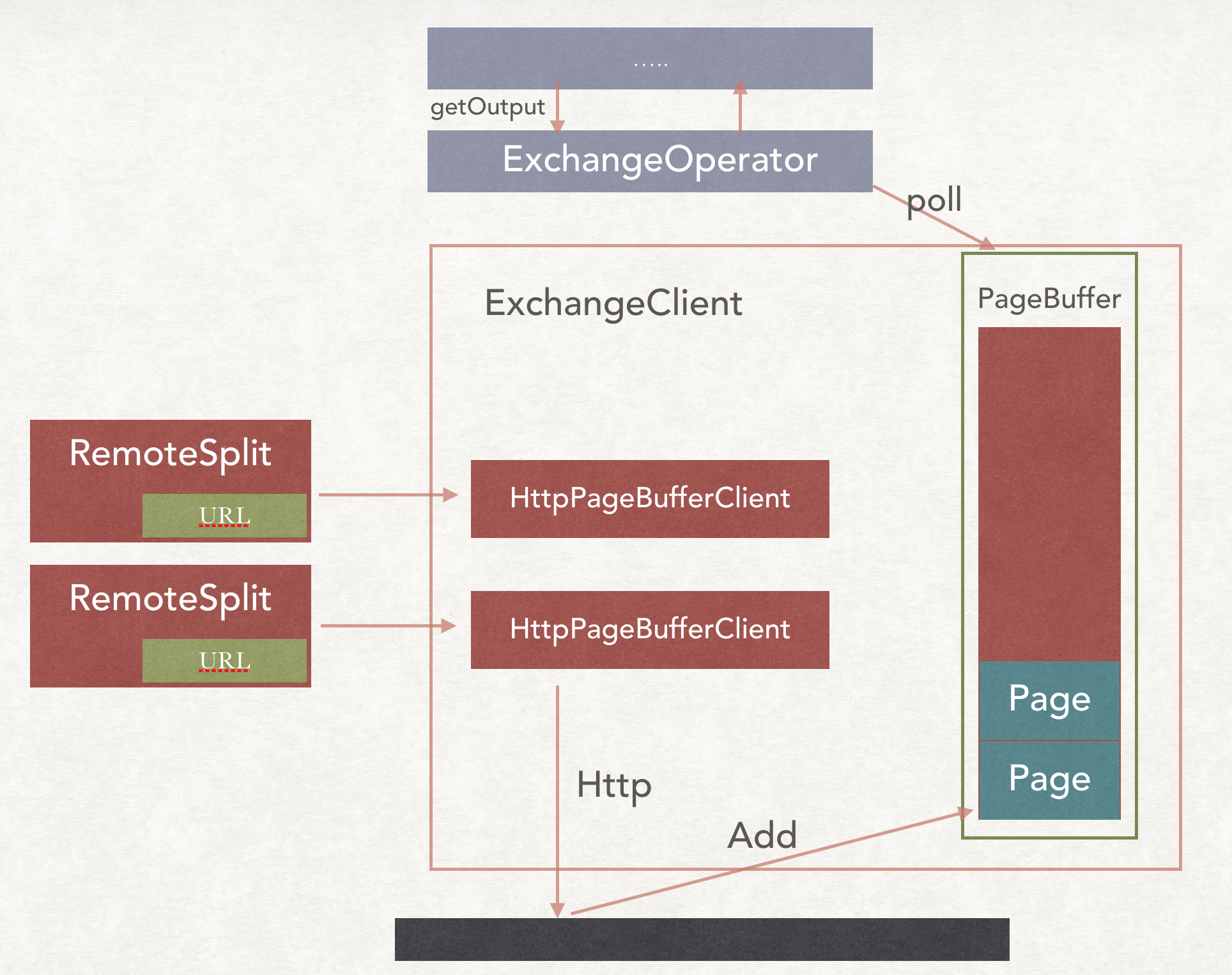
主体类
ExchangOperator
- 负责从下游的
Stage拉数据 - 创建
ExchangeOperator的时候, 会创建一个ExchangClient.
ExchangeOperator#getOutput(), 得到一个 page
1 | public Page getOutput() |
RemoteSplit
成员变量是一个标记数据位置的URL.
1 | public class RemoteSplit implements ConnectorSplit |
PageBufferClient
scheduleRequest
调用请求的地方, 每一次请求失败, 会有一个等待时间, 而且随着失败次数的增加, 这个等待的时间会越来越长. 在这个等待的时间内, 不会再去进行请求
ExchangeOperator#getOutput调用ExchangeClient#pollPage()pollPage会调用到PageBufferClient#sendGetResults()sendGetResults会调用到RpcShuffleClient, 有两种实现:HttpRpcShuffleClient/ThriftRpcShuffleClientHttpRpcShuffleClient#getResults- 上游的TaskResource提供了
{taskId}/results/{bufferId}/{token}接口用于提供数据, 以Page单位返回数据, token用于告知上游当前消费偏移量
1
2
3
4
5
6
7
8
9
10public ListenableFuture<PagesResponse> getResults(long token, DataSize maxResponseSize)
{
URI uriBase = asyncPageTransportLocation.orElse(location);
URI uri = uriBuilderFrom(uriBase).appendPath(String.valueOf(token)).build();
return httpClient.executeAsync(
prepareGet()
.setHeader(PRESTO_MAX_SIZE, maxResponseSize.toString())
.setUri(uri).build(),
new PageResponseHandler());
}PagesResponse中包含了serializedPage每个SqlTask在创建的时候都会创建一个对应的LazyOutputBuffer对象, 用于存放计算的结果, 等待下游过来拉取数据
- 某个Task还未被Presto Worker执行时就收到下游Task数据读取的请求时, LazyOutputBuffer会记录下该请求, 当该Task被执行并生成数据后, 再响应对应的请求:
List<PendingRead> pendingReads
- 某个Task还未被Presto Worker执行时就收到下游Task数据读取的请求时, LazyOutputBuffer会记录下该请求, 当该Task被执行并生成数据后, 再响应对应的请求:
PageBufferClient拉取到数据后会放到PageBuffer双端队列中, ExchangeClient从PageBuffer中读取数据
1
2
3
4
5
6
7
8ExchangeClient is the client on receiver side, used in operators requiring data exchange from other tasks, such as ExchangeOperator and ink MergeOperator.
For each sender that ExchangeClient receives data from, a PageBufferClient is used in ExchangeClient to communicate with the sender, i.e.
/ HttpPageBufferClient_1 - - - Remote Source 1
ExchangeClient -- HttpPageBufferClient_2 - - - Remote Source 2
\ ...
\ HttpPageBufferClient_n - - - Remote Source n
ExchangeClient流控
请求端流控
ExchangeClient 有一个long类型的bufferBytes, 用来标记当前的buffer中有多少buffer.
在scheduleRequestIfNecessary()方法中, 会把bufferBytes和maxBufferSize进行比较, 如果已经满足了, 那么就不会请求HttpPageBufferClient去请求数据.
OutputBuffer
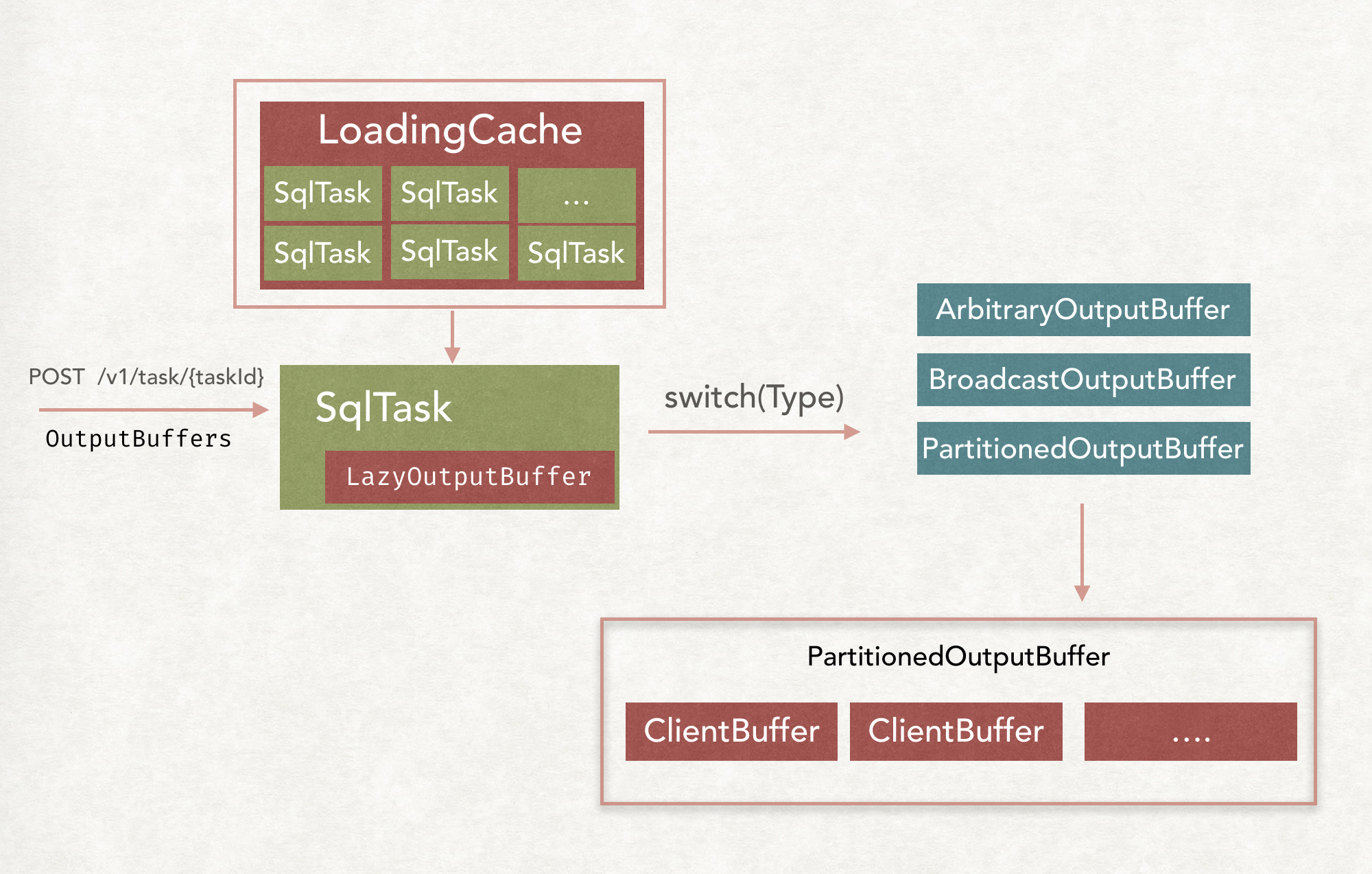
LazyOutputBuffer: 是一个门面模式, 包含了一个类别不同的OutputBuffe
具体是哪一种, 要根据OutputBuffer的类别来判定.
如果是Broadcast类别的, 就会创建BroadcastOutputBuffer, 如果是Partition类别的, 就会创建PartitionedOutputBuffer.
然后就会根据OutputBuffers的个数具体创建ClientBuffer.
然后在TaskOutputOperator或者是PartitionOutputOperator进行finish的时候, 都是把Page放到ClientBuffer中.
如果是BroadcastOutputBuffer类别的, 就是把PageReference放到所有的ClientBuffer中, 如果是Partition类别的, 就是放到指定的ClientBuffer中.
传输可靠性
下游去上游的Stage拿数据的接口是 @Get @Path("{taskId}/results/{bufferId}/{token}")
- taksId: 本 taskId
- bufferId: 标记下游的哪个
Task来拿的数据 - token
presto 模拟了Tcp中的Seq和Ack机制, 但是因为只有上游需要把数据传送给下游, 所以是半双工的, 保证了数据的可靠性
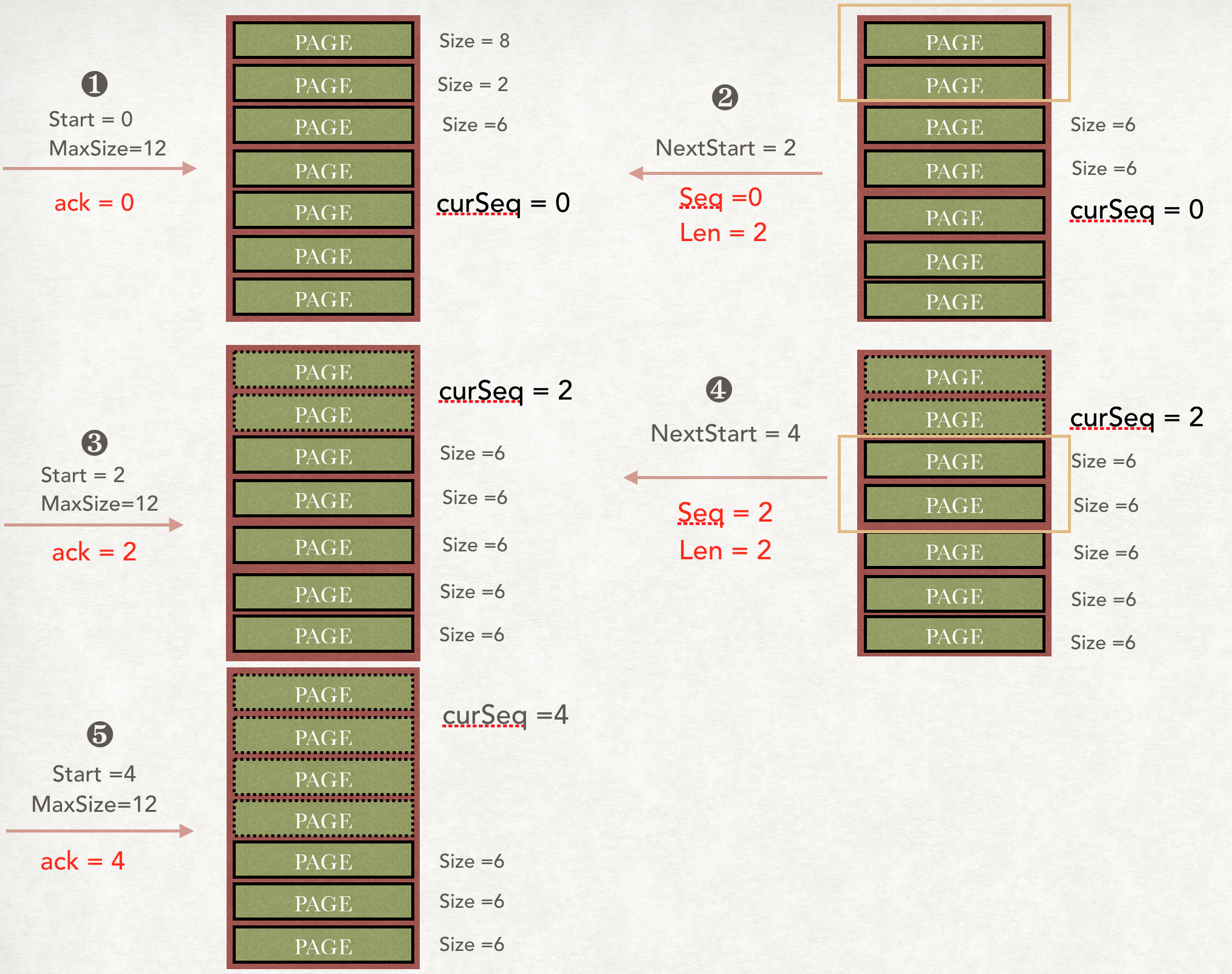
OutputBuffer流控
每一个BroadcastOutputBuffer或者PartitionedOutputBuffer都会有一个 maxBufferedBytes, 用来监控当前已经的buffer的大小.
每来一个Page, 把大小加进去, 每出一个Page把大小减去, 如果当前攒着的大小超过了阈值, 那么就返回Blocked, 把整个Driver给Block掉, 不去执行了.
对于 broadcast 场景: 每个ClientBuffer中其实都有一个Page的引用, 只有当所有的下游Task把对应的ClientBuffer里面的Page取走了才能把大小给减去, presto 采用引用计数的实现, 每add到Buffer中一次, 计数就加一, 每从buffer中移除一次, 计数就减一, 当为0的时候, 就调用回调把size减去.