if (pipelines.empty()) { pipeline->init(Pipe(std::make_shared<NullSource>(output_stream->header))); processors = collector.detachProcessors(); return pipeline; }
for (auto & cur_pipeline : pipelines) { /// Headers for union must be equal. /// But, just in case, convert it to the same header if not. if (!isCompatibleHeader(cur_pipeline->getHeader(), getOutputStream().header)) { auto converting_dag = ActionsDAG::makeConvertingActions( cur_pipeline->getHeader().getColumnsWithTypeAndName(), getOutputStream().header.getColumnsWithTypeAndName(), ActionsDAG::MatchColumnsMode::Name);
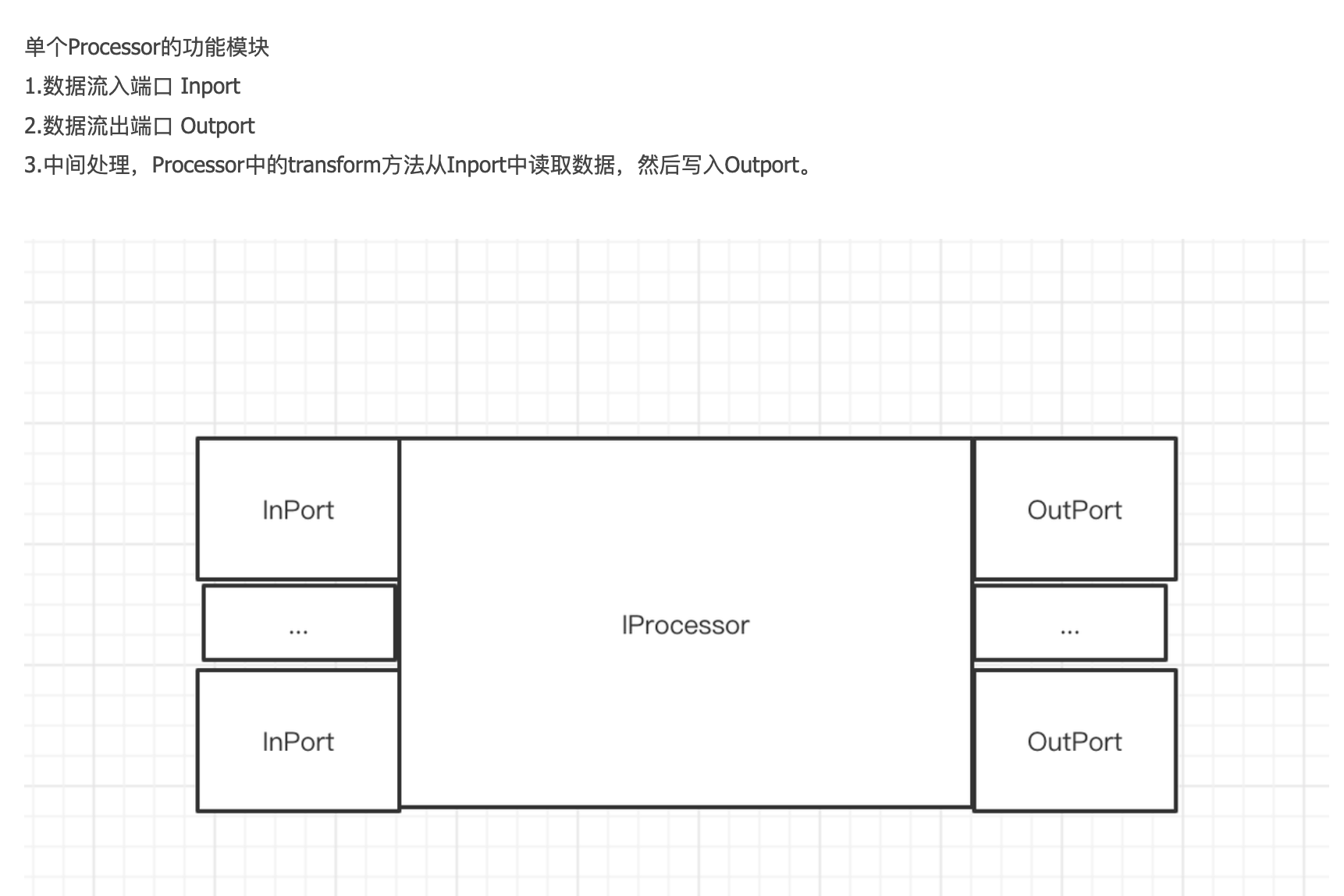
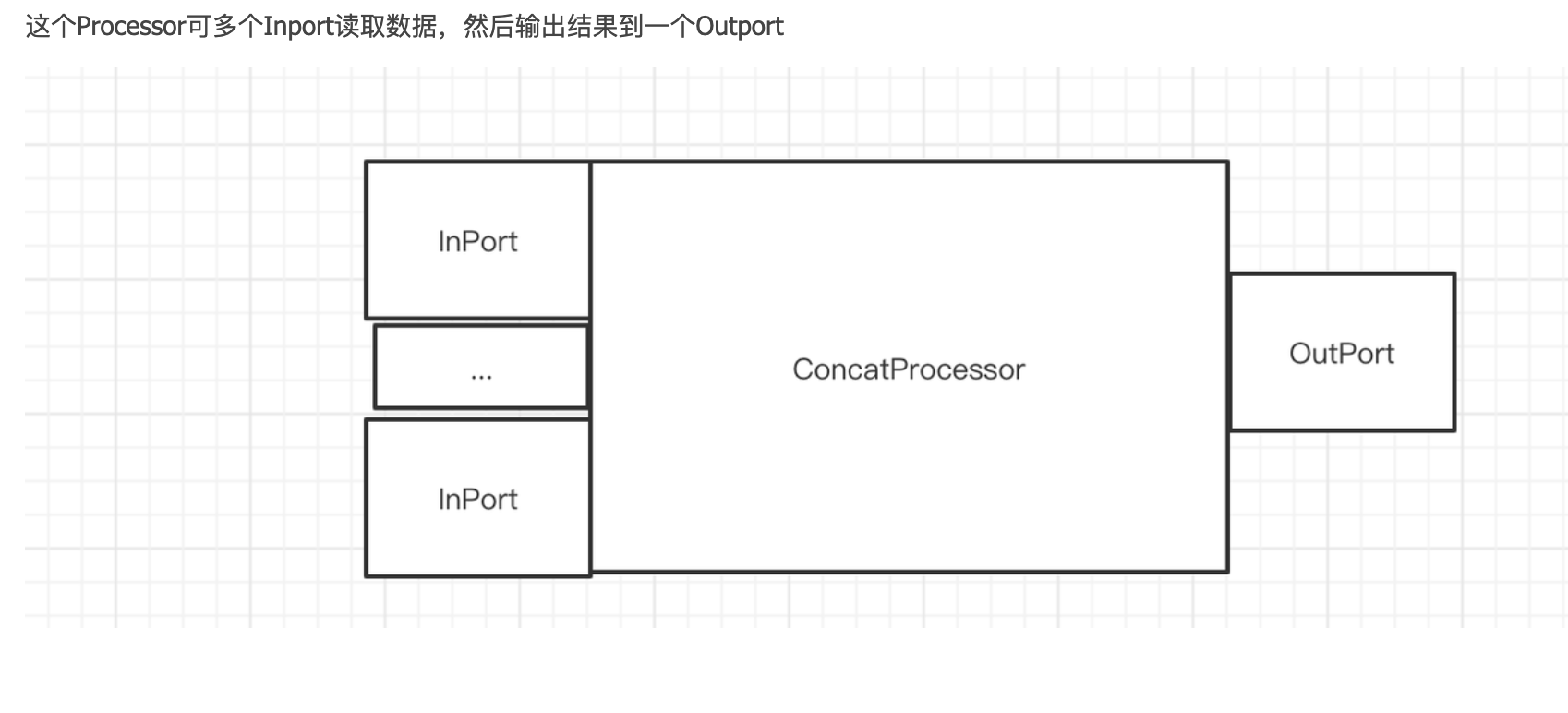
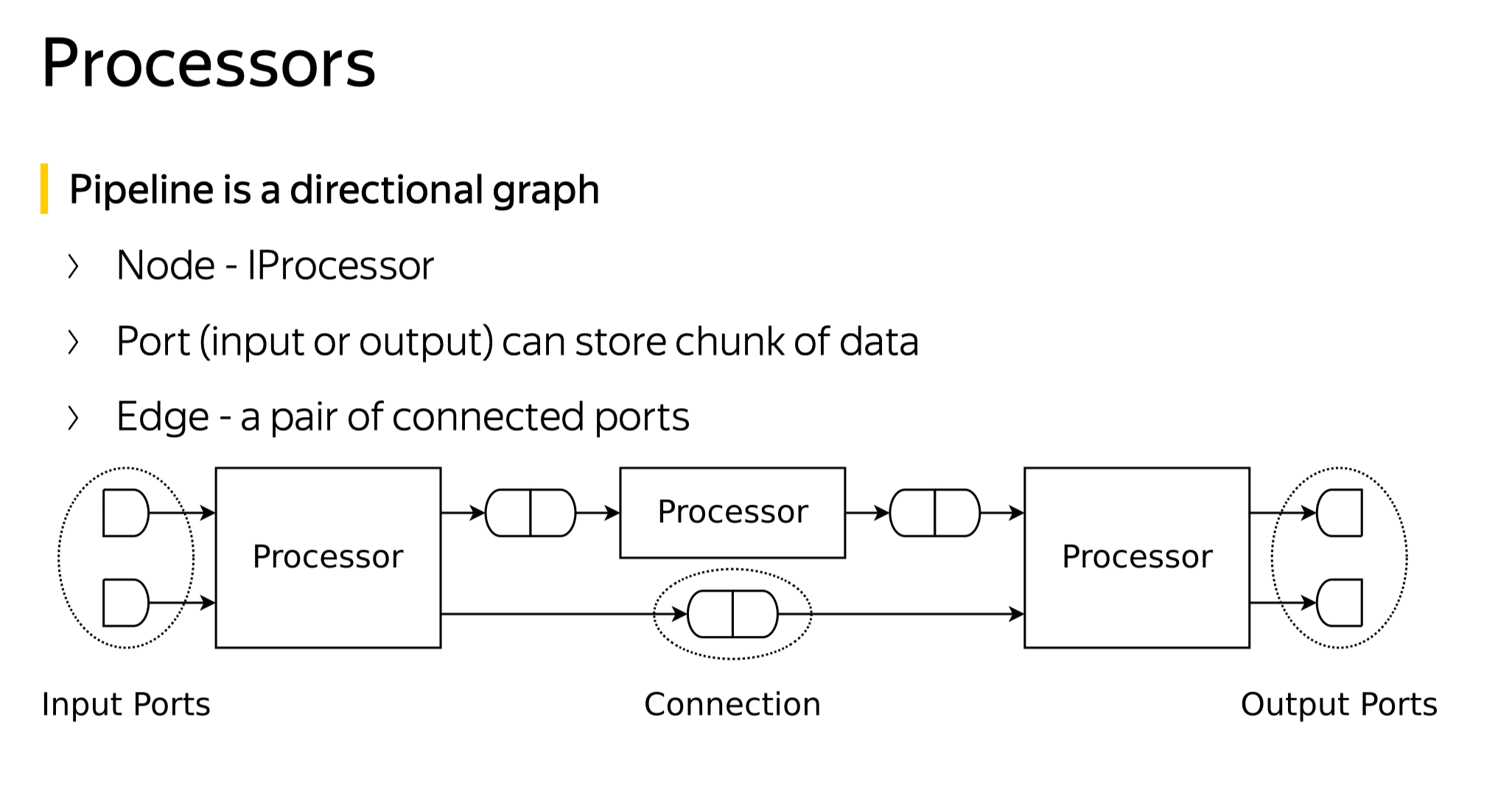
IProcessor(InputPorts inputs_, OutputPorts outputs_) : inputs(std::move(inputs_)), outputs(std::move(outputs_)) { for (auto & port : inputs) port.processor = this; for (auto & port : outputs) port.processor = this; }
/** Method 'prepare' is responsible for all cheap ("instantaneous": O(1) of data volume, no wait) calculations. * * It may access input and output ports, * indicate the need for work by another processor by returning NeedData or PortFull, * or indicate the absence of work by returning Finished or Unneeded, * it may pull data from input ports and push data to output ports. * * The method is not thread-safe and must be called from a single thread in one moment of time, * even for different connected processors. * * Instead of all long work (CPU calculations or waiting) it should just prepare all required data and return Ready or Async. * * Thread safety and parallel execution: * - no methods (prepare, work, schedule) of single object can be executed in parallel; * - method 'work' can be executed in parallel for different objects, even for connected processors; * - method 'prepare' cannot be executed in parallel even for different objects, * if they are connected (including indirectly) to each other by their ports; */ virtual Status prepare() /** You may call this method if 'prepare' returned Ready. * This method cannot access any ports. It should use only data that was prepared by 'prepare' method. * * Method work can be executed in parallel for different processors. */ virtualvoidwork() /** Executor must call this method when 'prepare' returned Async. * This method cannot access any ports. It should use only data that was prepared by 'prepare' method. * * This method should instantly return epollable file descriptor which will be readable when asynchronous job is done. * When descriptor is readable, method `work` is called to continue data processing. * * NOTE: it would be more logical to let `work()` return ASYNC status instead of prepare. This will get * prepare() -> work() -> schedule() -> work() -> schedule() -> .. -> work() -> prepare() * chain instead of * prepare() -> work() -> prepare() -> schedule() -> work() -> prepare() -> schedule() -> .. -> work() -> prepare() * * It is expected that executor epoll using level-triggered notifications. * Read all available data from descriptor before returning ASYNC. */ virtualintschedule() /** You must call this method if 'prepare' returned ExpandPipeline. * This method cannot access any port, but it can create new ports for current processor. * * Method should return set of new already connected processors. * All added processors must be connected only to each other or current processor. * * Method can't remove or reconnect existing ports, move data from/to port or perform calculations. * 'prepare' should be called again after expanding pipeline. */ virtual Processors expandPipeline() voidcancel() { is_cancelled = true; onCancel(); } protected: virtualvoidonCancel(){} private: IQueryPlanStep * query_plan_step = nullptr;
if (!skip_empty_chunks || output_data.chunk) has_output = true;
if (has_output && !output_data.chunk && getOutputPort().getHeader()) /// Support invariant that chunks must have the same number of columns as header. output_data.chunk = Chunk(getOutputPort().getHeader().cloneEmpty().getColumns(), 0); }
while (!updated_processors.empty() || !updated_edges.empty()) { std::optional<std::unique_lock<std::mutex>> stack_top_lock;
if (updated_processors.empty()) { auto * edge = updated_edges.top(); updated_edges.pop();
/// Here we have ownership on edge, but node can be concurrently accessed.
auto & node = *nodes[edge->to];
std::unique_lock lock(node.status_mutex);
ExecutingGraph::ExecStatus status = node.status;
if (status != ExecutingGraph::ExecStatus::Finished) { if (edge->backward) node.updated_output_ports.push_back(edge->output_port_number); else node.updated_input_ports.push_back(edge->input_port_number);
switch (node.last_processor_status) { case IProcessor::Status::NeedData: case IProcessor::Status::PortFull: { node.status = ExecutingGraph::ExecStatus::Idle; break; } case IProcessor::Status::Finished: { node.status = ExecutingGraph::ExecStatus::Finished; break; } case IProcessor::Status::Ready: { node.status = ExecutingGraph::ExecStatus::Executing; queue.push(&node); break; } case IProcessor::Status::Async: { node.status = ExecutingGraph::ExecStatus::Executing; async_queue.push(&node); break; } case IProcessor::Status::ExpandPipeline: { need_expand_pipeline = true; break; } }
if (!need_expand_pipeline) { /// If you wonder why edges are pushed in reverse order, /// it is because updated_edges is a stack, and we prefer to get from stack /// input ports firstly, and then outputs, both in-order. /// /// Actually, there should be no difference in which order we process edges. /// However, some tests are sensitive to it (e.g. something like SELECT 1 UNION ALL 2). /// Let's not break this behaviour so far.
for (auto it = node.post_updated_output_ports.rbegin(); it != node.post_updated_output_ports.rend(); ++it) { auto * edge = static_cast<ExecutingGraph::Edge *>(*it); updated_edges.push(edge); edge->update_info.trigger(); }
for (auto it = node.post_updated_input_ports.rbegin(); it != node.post_updated_input_ports.rend(); ++it) { auto * edge = static_cast<ExecutingGraph::Edge *>(*it); updated_edges.push(edge); edge->update_info.trigger(); }
boolPipelineExecutor::executeStep(std::atomic_bool * yield_flag) { if (!is_execution_initialized) { initializeExecution(1);
// Acquire slot until we are done single_thread_slot = slots->tryAcquire(); if (!single_thread_slot) abort(); // Unable to allocate slot for the first thread, but we just allocated at least one slot
if (yield_flag && *yield_flag) returntrue; }
executeStepImpl(0, yield_flag);
if (!tasks.isFinished()) returntrue;
/// Execution can be stopped because of exception. Check and rethrow if any. for (auto & node : graph->nodes) if (node->exception) std::rethrow_exception(node->exception);
while (!tasks.isFinished() && !yield) { /// First, find any processor to execute. /// Just traverse graph and prepare any processor. while (!tasks.isFinished() && !context.hasTask()) tasks.tryGetTask(context);
while (context.hasTask() && !yield) { if (tasks.isFinished()) break;