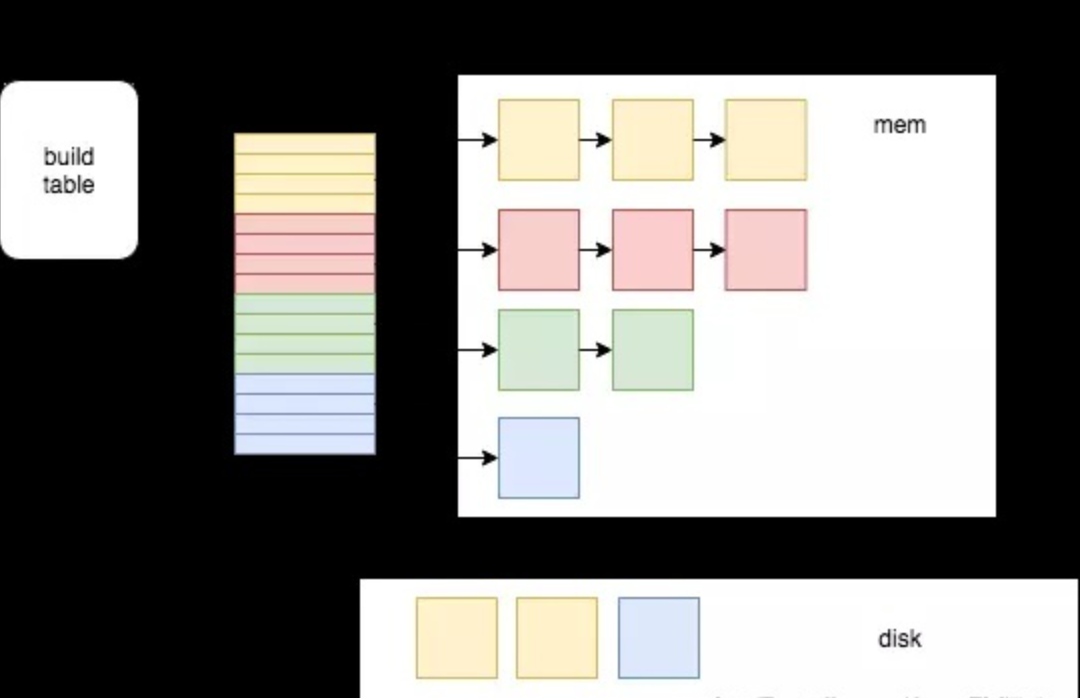
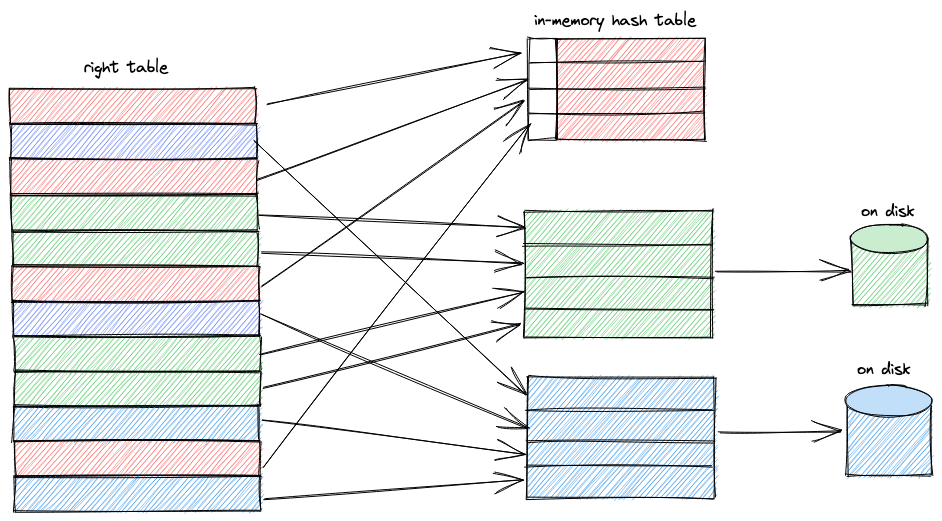
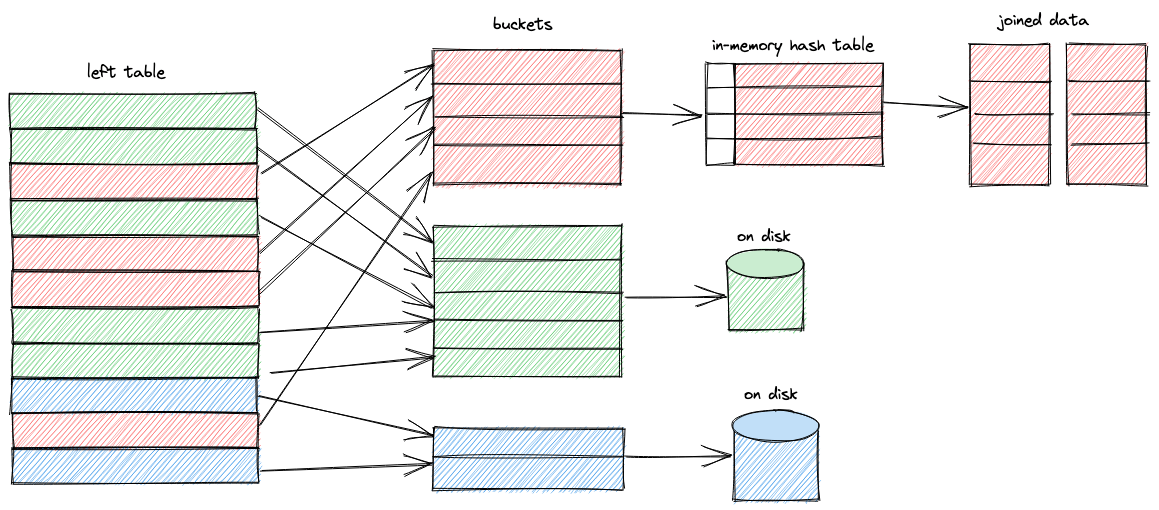
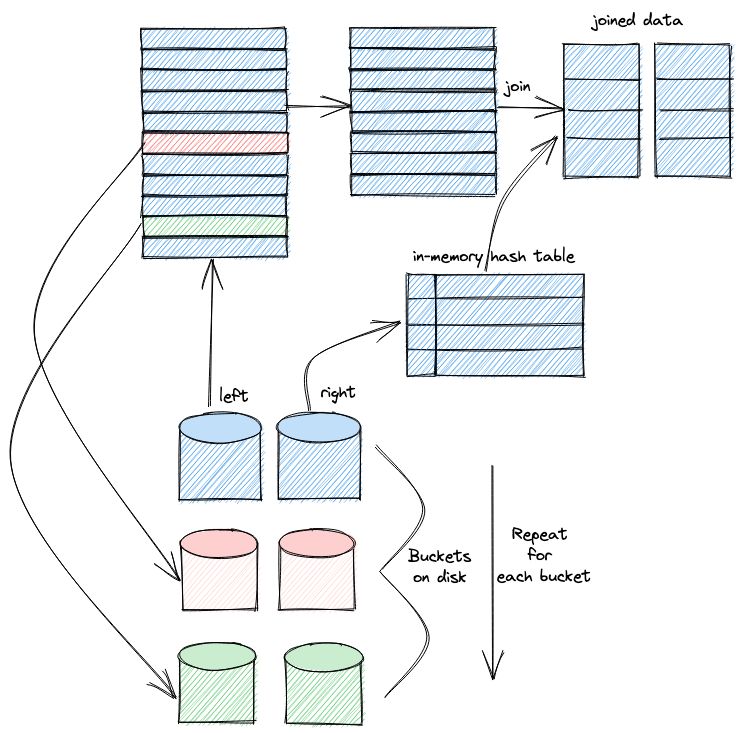
/** * Efficient and highly parallel implementation of external memory JOIN based on HashJoin. * Supports most of the JOIN modes, except CROSS and ASOF. * * The joining algorithm consists of three stages: * * 1) During the first stage we accumulate blocks of the right table via @addBlockToJoin. * Each input block is split into multiple buckets based on the hash of the row join keys. * The first bucket is added to the in-memory HashJoin, and the remaining buckets are written to disk for further processing. * When the size of HashJoin exceeds the limits, we double the number of buckets. * There can be multiple threads calling addBlockToJoin, just like @ConcurrentHashJoin. * * 2) At the second stage we process left table blocks via @joinBlock. * Again, each input block is split into multiple buckets by hash. * The first bucket is joined in-memory via HashJoin::joinBlock, and the remaining buckets are written to the disk. * * 3) When the last thread reading left table block finishes, the last stage begins. * Each @DelayedJoinedBlocksTransform calls repeatedly @getDelayedBlocks until there are no more unfinished buckets left. * Inside @getDelayedBlocks we select the next unprocessed bucket, load right table blocks from disk into in-memory HashJoin, * And then join them with left table blocks. * * After joining the left table blocks, we can load non-joined rows from the right table for RIGHT/FULL JOINs. * Note that non-joined rows are processed in multiple threads, unlike HashJoin/ConcurrentHashJoin/MergeJoin. */
SELECT query, formatReadableTimeDelta(query_duration_ms / 1000) AS query_duration, formatReadableSize(memory_usage) AS memory_usage, formatReadableQuantity(read_rows) AS read_rows, formatReadableSize(read_bytes) AS read_data FROM clusterAllReplicas(default, system.query_log) WHERE (type = 'QueryFinish') AND hasAll(tables, ['imdb_large.actors', 'imdb_large.roles']) ORDER BY initial_query_start_time DESC LIMIT 2 FORMAT Vertical;
Row 1: ────── query: SELECT * FROM actors AS a JOIN roles AS r ON a.id = r.actor_id FORMAT `Null` SETTINGS join_algorithm = 'grace_hash', grace_hash_join_initial_buckets = 3 query_duration: 13 seconds memory_usage: 3.72 GiB read_rows: 101.00 million read_data: 3.41 GiB
Row 2: ────── query: SELECT * FROM actors AS a JOIN roles AS r ON a.id = r.actor_id FORMAT `Null` SETTINGS join_algorithm = 'hash' query_duration: 5 seconds memory_usage: 8.96 GiB read_rows: 101.00 million read_data: 3.41 GiB
SELECT query, formatReadableTimeDelta(query_duration_ms / 1000) AS query_duration, formatReadableSize(memory_usage) AS memory_usage, formatReadableQuantity(read_rows) AS read_rows, formatReadableSize(read_bytes) AS read_data FROM clusterAllReplicas(default, system.query_log) WHERE (type = 'QueryFinish') AND hasAll(tables, ['imdb_large.actors', 'imdb_large.roles']) ORDER BY initial_query_start_time DESC LIMIT 2 FORMAT Vertical;
Row 1: ────── query: SELECT * FROM actors AS a JOIN roles AS r ON a.id = r.actor_id FORMAT `Null` SETTINGS join_algorithm = 'grace_hash', grace_hash_join_initial_buckets = 8 query_duration: 16 seconds memory_usage: 2.10 GiB read_rows: 101.00 million read_data: 3.41 GiB
Row 2: ────── query: SELECT * FROM actors AS a JOIN roles AS r ON a.id = r.actor_id FORMAT `Null` SETTINGS join_algorithm = 'grace_hash', grace_hash_join_initial_buckets = 3 query_duration: 13 seconds memory_usage: 3.72 GiB read_rows: 101.00 million read_data: 3.41 GiB