/// optimize_aggregation_in_order if (group_by_info) { ... }
if (!allow_to_use_two_level_group_by) { params.group_by_two_level_threshold = 0; params.group_by_two_level_threshold_bytes = 0; }
/** Two-level aggregation is useful in two cases: * 1. Parallel aggregation is done, and the results should be merged in parallel. * 2. An aggregation is done with store of temporary data on the disk, and they need to be merged in a memory efficient way. */ constauto src_header = pipeline.getHeader(); auto transform_params = std::make_shared<AggregatingTransformParams>(src_header, std::move(params), final);
// 默认为空,不关心GROUPING SETS modifier if (!grouping_sets_params.empty()) { ... }
// 不关心GROUP BY Optimization Depending on Table Sorting Key这个优化,即默认group_by_info == nullptr; if (group_by_info) { ... }
/// If there are several sources, then we perform parallel aggregation if (pipeline.getNumStreams() > 1) { /// Add resize transform to uniformly distribute data between aggregating streams. if (!storage_has_evenly_distributed_read) pipeline.resize(pipeline.getNumStreams(), true, true);
auto many_data = std::make_shared<ManyAggregatedData>(pipeline.getNumStreams());
/// We add the explicit resize here, but not in case of aggregating in order, since AIO don't use two-level hash tables and thus returns only buckets with bucket_number = -1. pipeline.resize(should_produce_results_in_order_of_bucket_number ? 1 : params.max_threads, true/* force */);
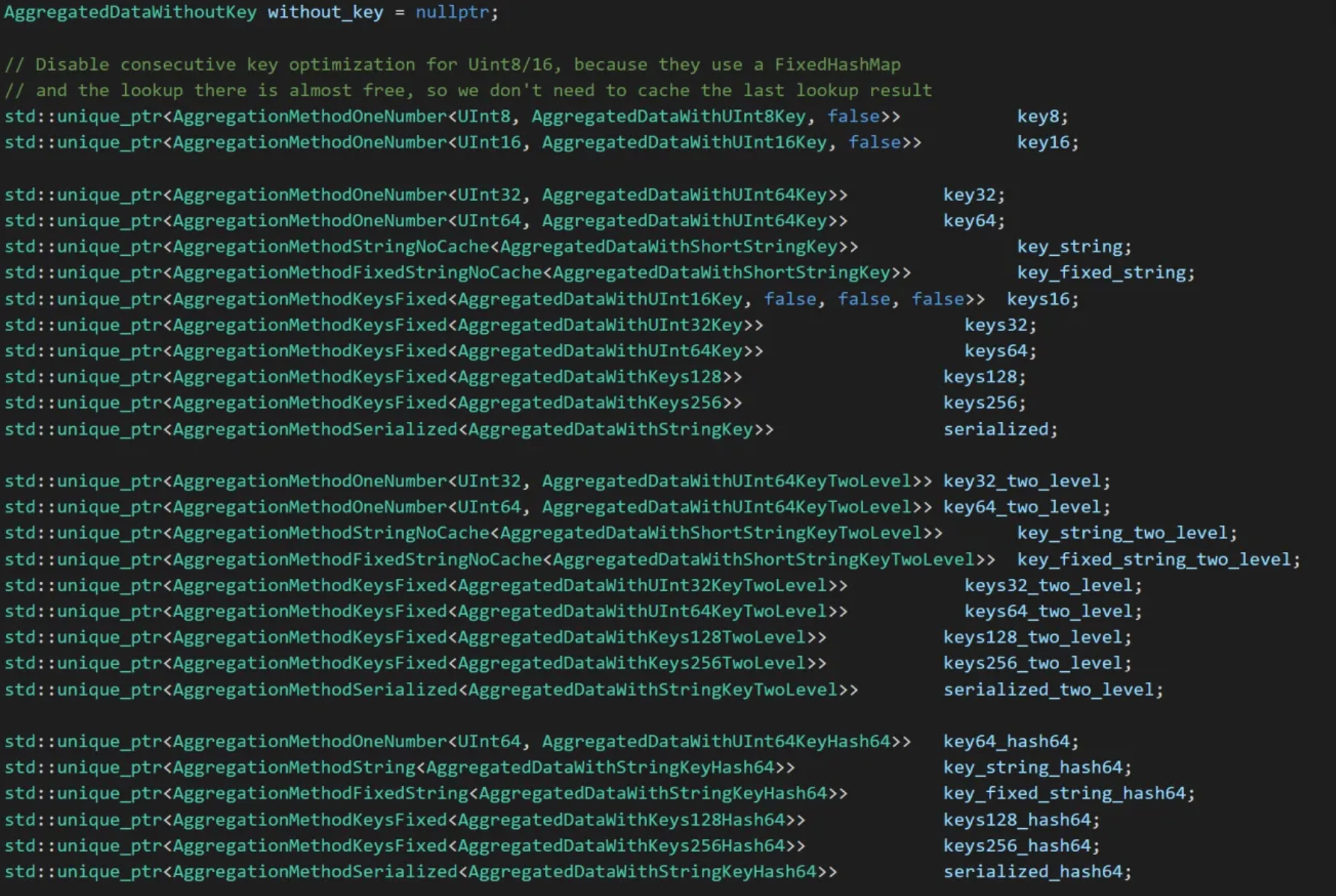
aggregator的预聚合操作,其内部数据是通过哈希表存储的,哈希表的键是“grouping key” value(举例:如果sql语句中group by b,那么哈希表的键是表中b的所有不同的值)。这个哈希表是动态的,随着键数量的增加,ClickHouse会将其切换到两级哈希表以提升性能;另外对于不同的键类型,ClickHouse提供了很多特化版本,以针对特定类型进行优化。
/// Generates chunks with aggregated data. /// In single level case, aggregates data itself. /// In two-level case, creates `ConvertingAggregatedToChunksSource` workers: /// /// ConvertingAggregatedToChunksSource -> /// ConvertingAggregatedToChunksSource -> ConvertingAggregatedToChunksTransform -> AggregatingTransform /// ConvertingAggregatedToChunksSource -> /// /// Result chunks guaranteed to be sorted by bucket number. class ConvertingAggregatedToChunksTransform : public IProcessor
Processors AggregatingTransform::expandPipeline() { if (processors.empty()) throwException("Can not expandPipeline in AggregatingTransform. This is a bug.", ErrorCodes::LOGICAL_ERROR); auto & out = processors.back()->getOutputs().front(); inputs.emplace_back(out.getHeader(), this); connect(out, inputs.back()); is_pipeline_created = true; return std::move(processors); }
aggregate_functions.resize(params.aggregates_size); for (size_t i = 0; i < params.aggregates_size; ++i) aggregate_functions[i] = params.aggregates[i].function.get();
/// Initialize sizes of aggregation states and its offsets. offsets_of_aggregate_states.resize(params.aggregates_size); total_size_of_aggregate_states = 0; all_aggregates_has_trivial_destructor = true;
// aggregate_states will be aligned as below: // |<-- state_1 -->|<-- pad_1 -->|<-- state_2 -->|<-- pad_2 -->| ..... // // pad_N will be used to match alignment requirement for each next state. // The address of state_1 is aligned based on maximum alignment requirements in states for (size_t i = 0; i < params.aggregates_size; ++i) { offsets_of_aggregate_states[i] = total_size_of_aggregate_states;
// aggregate states are aligned based on maximum requirement align_aggregate_states = std::max(align_aggregate_states, params.aggregates[i].function->alignOfData());
// If not the last aggregate_state, we need pad it so that next aggregate_state will be aligned. if (i + 1 < params.aggregates_size) { size_t alignment_of_next_state = params.aggregates[i + 1].function->alignOfData(); if ((alignment_of_next_state & (alignment_of_next_state - 1)) != 0) throwException("Logical error: alignOfData is not 2^N", ErrorCodes::LOGICAL_ERROR);
/// Extend total_size to next alignment requirement /// Add padding by rounding up 'total_size_of_aggregate_states' to be a multiplier of alignment_of_next_state. total_size_of_aggregate_states = (total_size_of_aggregate_states + alignment_of_next_state - 1) / alignment_of_next_state * alignment_of_next_state; }
if (!params.aggregates[i].function->hasTrivialDestructor()) all_aggregates_has_trivial_destructor = false; }
AggregatedDataVariants::Type Aggregator::chooseAggregationMethod() { /// If no keys. All aggregating to single row. if (params.keys_size == 0) return AggregatedDataVariants::Type::without_key; ...
if (has_nullable_key) { if (params.keys_size == num_fixed_contiguous_keys && !has_low_cardinality) { ... }
if (has_low_cardinality && params.keys_size == 1) { ... } }
/// No key has been found to be nullable.
/// Single numeric key. if (params.keys_size == 1 && types_removed_nullable[0]->isValueRepresentedByNumber()) { ... }
if (params.keys_size == 1 && isFixedString(types_removed_nullable[0])) { ... }
/// If all keys fits in N bits, will use hash table with all keys packed (placed contiguously) to single N-bit key. if (params.keys_size == num_fixed_contiguous_keys) { ... }
/// If single string key - will use hash table with references to it. Strings itself are stored separately in Arena. if (params.keys_size == 1 && isString(types_removed_nullable[0])) { ... }
boolAggregator::executeOnBlock(Columns columns, size_t row_begin, size_t row_end, AggregatedDataVariants & result, ColumnRawPtrs & key_columns, AggregateColumns & aggregate_columns, bool & no_more_keys)const { /// `result` will destroy the states of aggregate functions in the destructor result.aggregator = this;
/// How to perform the aggregation? if (result.empty()) { initDataVariantsWithSizeHint(result, method_chosen, params); result.keys_size = params.keys_size; result.key_sizes = key_sizes; LOG_TRACE(log, "Aggregation method: {}", result.getMethodName()); }
/** Constant columns are not supported directly during aggregation. * To make them work anyway, we materialize them. */ Columns materialized_columns;
/// Remember the columns we will work with for (size_t i = 0; i < params.keys_size; ++i) { materialized_columns.push_back(recursiveRemoveSparse(columns.at(keys_positions[i]))->convertToFullColumnIfConst()); key_columns[i] = materialized_columns.back().get(); ... }
if ((params.overflow_row || result.type == AggregatedDataVariants::Type::without_key) && !result.without_key) { AggregateDataPtr place = result.aggregates_pool->alignedAlloc(total_size_of_aggregate_states, align_aggregate_states); createAggregateStates(place); result.without_key = place; }
if (result.type == AggregatedDataVariants::Type::without_key) { executeWithoutKeyImpl<false>(result.without_key, row_begin, row_end, aggregate_functions_instructions.data(), result.aggregates_pool); } else { /// This is where data is written that does not fit in `max_rows_to_group_by` with `group_by_overflow_mode = any`. AggregateDataPtr overflow_row_ptr = params.overflow_row ? result.without_key : nullptr; executeImpl(result, row_begin, row_end, key_columns, aggregate_functions_instructions.data(), no_more_keys, overflow_row_ptr); }
/// Here all the results in the sum are taken into account, from different threads. auto result_size_bytes = current_memory_usage - memory_usage_before_aggregation;
/** Converting to a two-level data structure. * It allows you to make, in the subsequent, an effective merge - either economical from memory or parallel. */ if (result.isConvertibleToTwoLevel() && worth_convert_to_two_level) result.convertToTwoLevel();
/// Checking the constraints. if (!checkLimits(result_size, no_more_keys)) returnfalse;
/** Flush data to disk if too much RAM is consumed. * Data can only be flushed to disk if a two-level aggregation structure is used. */ if (params.max_bytes_before_external_group_by && result.isTwoLevel() && current_memory_usage > static_cast<Int64>(params.max_bytes_before_external_group_by) && worth_convert_to_two_level) { size_t size = current_memory_usage + params.min_free_disk_space; writeToTemporaryFile(result, size); }
template <bool no_more_keys, bool use_compiled_functions, bool prefetch, typename Method> void NO_INLINE Aggregator::executeImplBatch( Method & method, typename Method::State & state, Arena * aggregates_pool, size_t row_begin, size_t row_end, AggregateFunctionInstruction * aggregate_instructions, AggregateDataPtr overflow_row)const { ... /// NOTE: only row_end-row_start is required, but: /// - this affects only optimize_aggregation_in_order, /// - this is just a pointer, so it should not be significant, /// - and plus this will require other changes in the interface. std::unique_ptr<AggregateDataPtr[]> places(new AggregateDataPtr[row_end]);
/// For all rows. for (size_t i = row_begin; i < row_end; ++i) { AggregateDataPtr aggregate_data = nullptr;
ifconstexpr(!no_more_keys) { ... auto emplace_result = state.emplaceKey(method.data, i, *aggregates_pool);
/// If a new key is inserted, initialize the states of the aggregate functions, and possibly something related to the key. if (emplace_result.isInserted()) { /// exception-safety - if you can not allocate memory or create states, then destructors will not be called. emplace_result.setMapped(nullptr);
assert(aggregate_data != nullptr); } else { /// Add only if the key already exists. auto find_result = state.findKey(method.data, i, *aggregates_pool); if (find_result.isFound()) aggregate_data = find_result.getMapped(); else aggregate_data = overflow_row; }
places[i] = aggregate_data; } ... /// Add values to the aggregate functions. for (size_t i = 0; i < aggregate_functions.size(); ++i) { AggregateFunctionInstruction * inst = aggregate_instructions + i;
structParams { /// Data structure of source blocks. Block src_header; /// Data structure of intermediate blocks before merge. Block intermediate_header;
/// What to count. const ColumnNumbers keys; const AggregateDescriptions aggregates; constsize_t keys_size; constsize_t aggregates_size;
/// The settings of approximate calculation of GROUP BY. constbool overflow_row; /// Do we need to put into AggregatedDataVariants::without_key aggregates for keys that are not in max_rows_to_group_by. constsize_t max_rows_to_group_by; const OverflowMode group_by_overflow_mode;
/// Settings to flush temporary data to the filesystem (external aggregation). constsize_t max_bytes_before_external_group_by; /// 0 - do not use external aggregation.
/// Return empty result when aggregating without keys on empty set. bool empty_result_for_aggregation_by_empty_set;
VolumePtr tmp_volume;
/// Settings is used to determine cache size. No threads are created. size_t max_threads;
/// Aggregate the source. Get the result in the form of one of the data structures. voidexecute(const BlockInputStreamPtr & stream, AggregatedDataVariants & result);
using AggregateColumns = std::vector<ColumnRawPtrs>; using AggregateColumnsData = std::vector<ColumnAggregateFunction::Container *>; using AggregateColumnsConstData = std::vector<const ColumnAggregateFunction::Container *>; using AggregateFunctionsPlainPtrs = std::vector<IAggregateFunction *>;
/// Process one block. Return false if the processing should be aborted (with group_by_overflow_mode = 'break'). boolexecuteOnBlock(const Block & block, AggregatedDataVariants & result, ColumnRawPtrs & key_columns, AggregateColumns & aggregate_columns, /// Passed to not create them anew for each block bool & no_more_keys);
boolexecuteOnBlock(Columns columns, UInt64 num_rows, AggregatedDataVariants & result, ColumnRawPtrs & key_columns, AggregateColumns & aggregate_columns, /// Passed to not create them anew for each block bool & no_more_keys);
/** Convert the aggregation data structure into a block. * If overflow_row = true, then aggregates for rows that are not included in max_rows_to_group_by are put in the first block. * * If final = false, then ColumnAggregateFunction is created as the aggregation columns with the state of the calculations, * which can then be combined with other states (for distributed query processing). * If final = true, then columns with ready values are created as aggregate columns. */ BlocksList convertToBlocks(AggregatedDataVariants & data_variants, boolfinal, size_t max_threads)const;
/** Merge several aggregation data structures and output the result as a block stream. */ std::unique_ptr<IBlockInputStream> mergeAndConvertToBlocks(ManyAggregatedDataVariants & data_variants, boolfinal, size_t max_threads)const; ManyAggregatedDataVariants prepareVariantsToMerge(ManyAggregatedDataVariants & data_variants)const;
/** Merge the stream of partially aggregated blocks into one data structure. * (Pre-aggregate several blocks that represent the result of independent aggregations from remote servers.) */ voidmergeStream(const BlockInputStreamPtr & stream, AggregatedDataVariants & result, size_t max_threads);
using BucketToBlocks = std::map<Int32, BlocksList>; /// Merge partially aggregated blocks separated to buckets into one data structure. voidmergeBlocks(BucketToBlocks bucket_to_blocks, AggregatedDataVariants & result, size_t max_threads);
/// Merge several partially aggregated blocks into one. /// Precondition: for all blocks block.info.is_overflows flag must be the same. /// (either all blocks are from overflow data or none blocks are). /// The resulting block has the same value of is_overflows flag. Block mergeBlocks(BlocksList & blocks, boolfinal);
boolAggregator::executeOnBlock(Columns columns, UInt64 num_rows, AggregatedDataVariants & result, ColumnRawPtrs & key_columns, AggregateColumns & aggregate_columns, bool & no_more_keys) { /// `result` will destroy the states of aggregate functions in the destructor result.aggregator = this;
/// How to perform the aggregation? if (result.empty()) { result.init(method_chosen); result.keys_size = params.keys_size; result.key_sizes = key_sizes; LOG_TRACE(log, "Aggregation method: " << result.getMethodName()); }
for (size_t i = 0; i < params.aggregates_size; ++i) aggregate_columns[i].resize(params.aggregates[i].arguments.size());
/** Constant columns are not supported directly during aggregation. * To make them work anyway, we materialize them. */ Columns materialized_columns;
/// Remember the columns we will work with for (size_t i = 0; i < params.keys_size; ++i) { materialized_columns.push_back(columns.at(params.keys[i])->convertToFullColumnIfConst()); key_columns[i] = materialized_columns.back().get();
if (!result.isLowCardinality()) { auto column_no_lc = recursiveRemoveLowCardinality(key_columns[i]->getPtr()); if (column_no_lc.get() != key_columns[i]) { materialized_columns.emplace_back(std::move(column_no_lc)); key_columns[i] = materialized_columns.back().get(); } } }
/// For all rows. for (size_t i = 0; i < rows; ++i) { AggregateDataPtr aggregate_data = nullptr;
auto emplace_result = state.emplaceKey(method.data, i, *aggregates_pool);
/// If a new key is inserted, initialize the states of the aggregate functions, and possibly something related to the key. if (emplace_result.isInserted()) { /// exception-safety - if you can not allocate memory or create states, then destructors will not be called. emplace_result.setMapped(nullptr);
/** Create empty data for aggregation with `placement new` at the specified location. * You will have to destroy them using the `destroy` method. */ virtualvoidcreate(AggregateDataPtr place)const= 0;
/// Delete data for aggregation. virtualvoiddestroy(AggregateDataPtr place)constnoexcept= 0;
/** Adds a value into aggregation data on which place points to. * columns points to columns containing arguments of aggregation function. * row_num is number of row which should be added. * Additional parameter arena should be used instead of standard memory allocator if the addition requires memory allocation. */ virtualvoidadd(AggregateDataPtr place, const IColumn ** columns, size_t row_num, Arena * arena)const= 0;
/// Merges state (on which place points to) with other state of current aggregation function. virtualvoidmerge(AggregateDataPtr place, ConstAggregateDataPtr rhs, Arena * arena)const= 0;
/** Contains a loop with calls to "add" function. You can collect arguments into array "places" * and do a single call to "addBatch" for devirtualization and inlining. */ virtualvoidaddBatch(size_t batch_size, AggregateDataPtr * places, size_t place_offset, const IColumn ** columns, Arena * arena)const= 0;
/// Inserts results into a column. virtualvoidinsertResultInto(ConstAggregateDataPtr place, IColumn & to)const= 0;
首先看聚合节点Aggregator是如何调用insertResultInto函数的
1 2 3 4 5 6 7 8 9
data.forEachValue([&](const auto & key, auto & mapped) { method.insertKeyIntoColumns(key, key_columns, key_sizes);
for (size_t i = 0; i < params.aggregates_size; ++i) aggregate_functions[i]->insertResultInto( mapped + offsets_of_aggregate_states[i], *final_aggregate_columns[i]); });