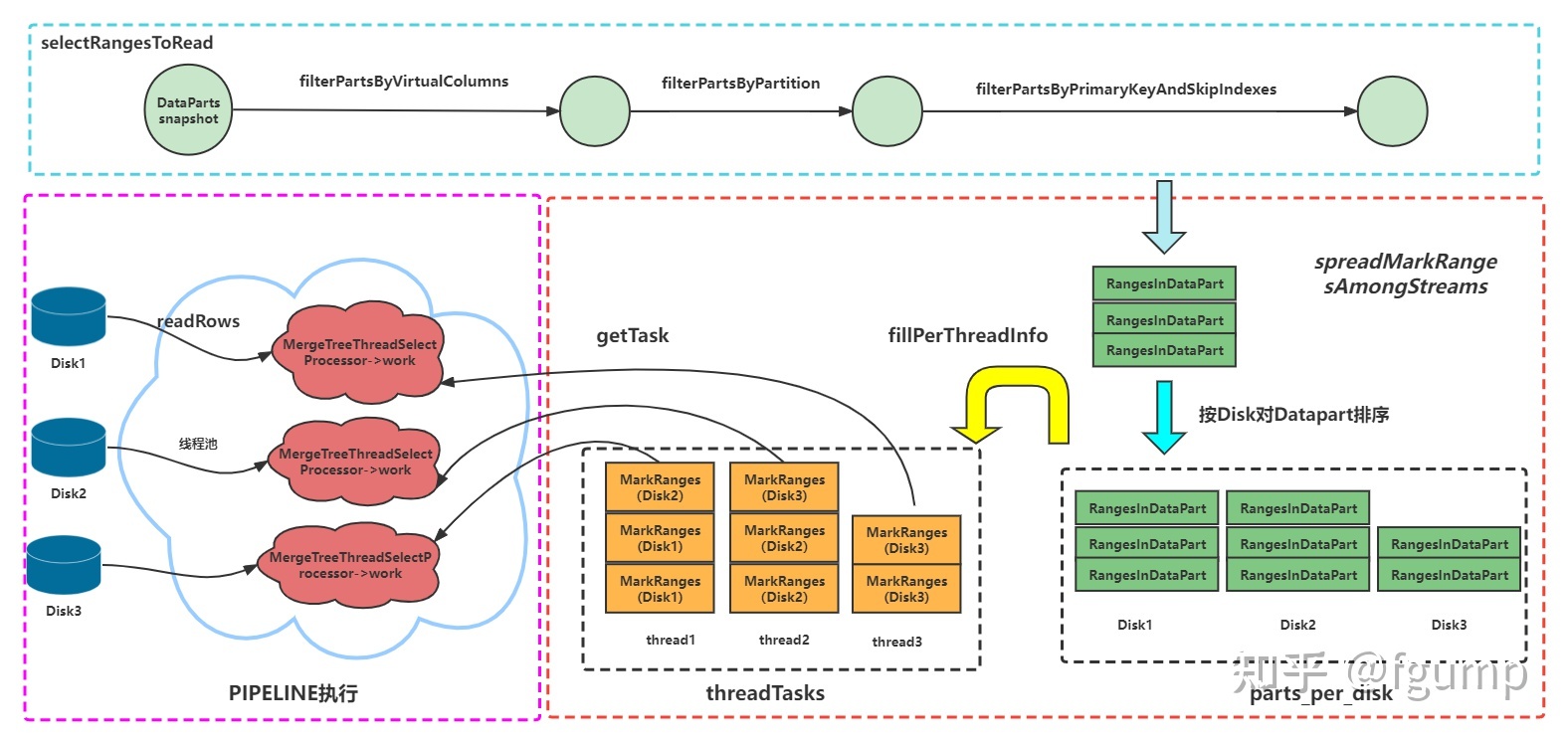
Pipe ReadFromMergeTree::readFromPool( RangesInDataParts parts_with_range, Names required_columns, size_t max_streams, size_t min_marks_for_concurrent_read, bool use_uncompressed_cache) { auto pool = std::make_shared<MergeTreeReadPool>(...); for (size_t i = 0; i < max_streams; ++i) { auto source = std::make_shared<MergeTreeThreadSelectProcessor>( i, pool, ....; pipes.emplace_back(std::move(source)); } return Pipe::unitePipes(std::move(pipes)); }
for (size_t i = 0; i < parts.size(); ++i) { PartInfo part_info{parts[i], per_part_sum_marks[i], i}; if (parts[i].data_part->isStoredOnDisk()) parts_per_disk[parts[i].data_part->volume->getDisk()->getName()].push_back(std::move(part_info)); else parts_per_disk[""].push_back(std::move(part_info)); }
for (auto & info : parts_per_disk) parts_queue.push(std::move(info.second)); }
// 遍历每一个线程,为每一个线程分配任务 for (size_t i = 0; i < threads && !parts_queue.empty(); ++i) { auto need_marks = min_marks_per_thread;
while (need_marks > 0 && !parts_queue.empty()) { auto & current_parts = parts_queue.front(); RangesInDataPart & part = current_parts.back().part; size_t & marks_in_part = current_parts.back().sum_marks; constauto part_idx = current_parts.back().part_idx;
/// Do not get too few rows from part. if (marks_in_part >= min_marks_for_concurrent_read && need_marks < min_marks_for_concurrent_read) need_marks = min_marks_for_concurrent_read;
/// Do not leave too few rows in part for next time. if (marks_in_part > need_marks && marks_in_part - need_marks < min_marks_for_concurrent_read) need_marks = marks_in_part;
/// Get whole part to read if it is small enough. if (marks_in_part <= need_marks) { ranges_to_get_from_part = part.ranges; marks_in_ranges = marks_in_part;
need_marks -= marks_in_part; current_parts.pop_back(); if (current_parts.empty()) parts_queue.pop(); } else { /// Loop through part ranges. while (need_marks > 0) { if (part.ranges.empty()) throwException("Unexpected end of ranges while spreading marks among threads", ErrorCodes::LOGICAL_ERROR);
... /// Do not leave too little rows in part for next time. // 如果此次获取到的range后,剩下的mark比较少,那么就一次行读整个DataPart,提高效率。 if (marks_in_part > need_marks && marks_in_part - need_marks < min_marks_to_read) need_marks = marks_in_part;
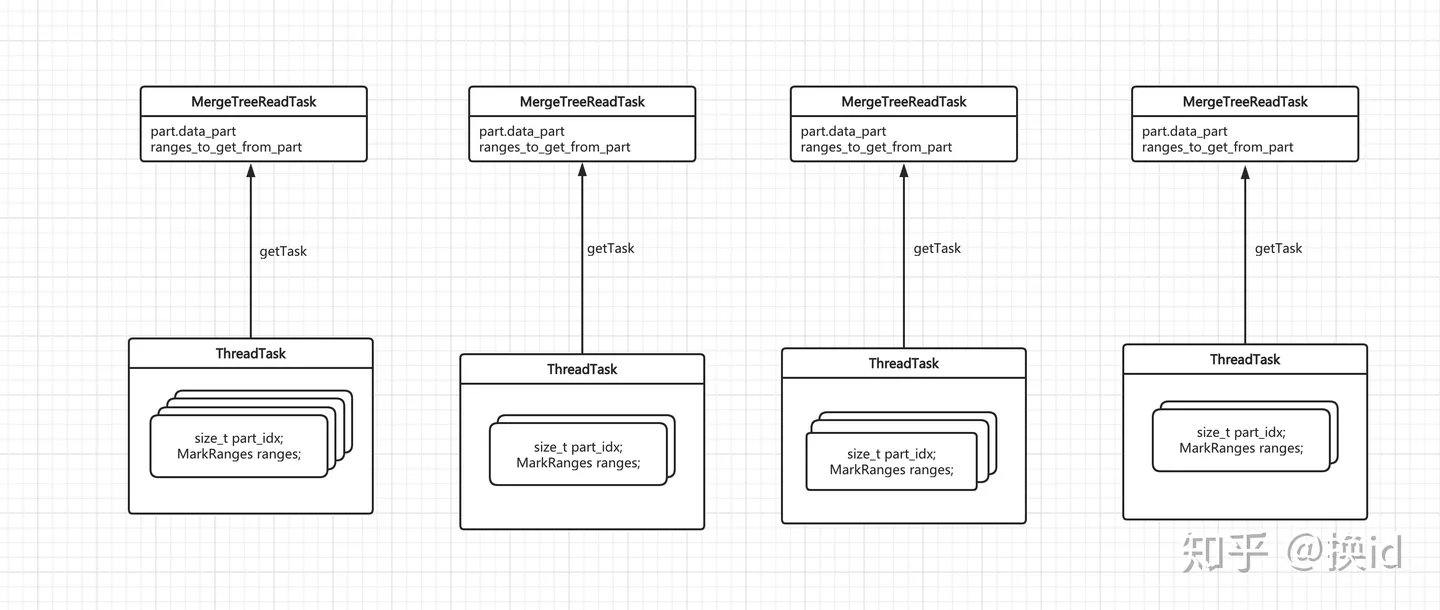
MarkRanges ranges_to_get_from_part;
/// Get whole part to read if it is small enough. //DataPart本身含有的mark总数就比较少,也一次性的读取整个DataPart if (marks_in_part <= need_marks) { constauto marks_to_get_from_range = marks_in_part; ranges_to_get_from_part = thread_task.ranges;
if (thread_tasks.sum_marks_in_parts.empty()) remaining_thread_tasks.erase(thread_idx); } else {
/// Loop through part ranges. // 遍历这个DataPart的range,找到足够数量的mark然后返回。 while (need_marks > 0 && !thread_task.ranges.empty()) { auto & range = thread_task.ranges.front();