/// Processor needs some data at its inputs to proceed. /// You need to run another processor to generate required input and then call 'prepare' again. NeedData,
/// Processor cannot proceed because output port is full or not isNeeded(). /// You need to transfer data from output port to the input port of another processor and then call 'prepare' again. PortFull,
/// All work is done (all data is processed or all output are closed), nothing more to do. Finished,
/// No one needs data on output ports. /// Unneeded,
/// You may call 'work' method and processor will do some work synchronously. Ready,
/// You may call 'schedule' method and processor will return descriptor. /// You need to poll this descriptor and call work() afterwards. Async,
/// Processor wants to add other processors to pipeline. /// New processors must be obtained by expandPipeline() call. ExpandPipeline,
IProcessor::Status AggregatingTransform::prepare() { /// There are one or two input ports. /// The first one is used at aggregation step, the second one - while reading merged data from ConvertingAggregated
auto & output = outputs.front(); /// Last output is current. All other outputs should already be closed. auto & input = inputs.back();
/// Check can output. if (output.isFinished()) { input.close(); return Status::Finished; }
if (!output.canPush()) { input.setNotNeeded(); return Status::PortFull; }
/// Finish data processing, prepare to generating. if (is_consume_finished && !is_generate_initialized) { /// Close input port in case max_rows_to_group_by was reached but not all data was read. inputs.front().close();
return Status::Ready; }
if (is_generate_initialized && !is_pipeline_created && !processors.empty()) return Status::ExpandPipeline;
/// Only possible while consuming. if (read_current_chunk) return Status::Ready;
/// Get chunk from input. if (input.isFinished()) { if (is_consume_finished) { output.finish(); return Status::Finished; } else { /// Finish data processing and create another pipe. is_consume_finished = true; return Status::Ready; } }
if (!input.hasData()) { input.setNeeded(); return Status::NeedData; }
/// Get chunk from input. if (input.isFinished()) { if (is_consume_finished) { output.finish(); return Status::Finished; } else { /// Finish data processing and create another pipe. is_consume_finished = true; return Status::Ready; } }
Processors AggregatingTransform::expandPipeline() { if (processors.empty()) throwException(ErrorCodes::LOGICAL_ERROR, "Can not expandPipeline in AggregatingTransform. This is a bug."); auto & out = processors.back()->getOutputs().front(); inputs.emplace_back(out.getHeader(), this); connect(out, inputs.back()); is_pipeline_created = true; return std::move(processors); }
/// Is used for default implementation in HashMethodBase. FieldType getKeyHolder(size_t row, Arena &)const{ return unalignedLoad<FieldType>(vec + row * sizeof(FieldType)); }
/// For all rows. for (size_t i = 0; i < rows; ++i) { AggregateDataPtr aggregate_data = nullptr; auto emplace_result = state.emplaceKey(method.data, i, *aggregates_pool); /// If a new key is inserted, initialize the states of the aggregate functions, and possibly something related to the key. if (emplace_result.isInserted()) { /// exception-safety - if you can not allocate memory or create states, then destructors will not be called. emplace_result.setMapped(nullptr); aggregate_data = aggregates_pool->alignedAlloc(total_size_of_aggregate_states, align_aggregate_states); createAggregateStates(aggregate_data); emplace_result.setMapped(aggregate_data); } places[i] = aggregate_data; }
for (size_t j = 0; j < params.aggregates_size; ++j) { try { /** An exception may occur if there is a shortage of memory. * In order that then everything is properly destroyed, we "roll back" some of the created states. * The code is not very convenient. */ aggregate_functions[j]->create(aggregate_data + offsets_of_aggregate_states[j]); } catch (...) { for (size_t rollback_j = 0; rollback_j < j; ++rollback_j) { ifconstexpr(skip_compiled_aggregate_functions) if(is_aggregate_function_compiled[j]) continue;
using AggregateDataPtr = char *; voidcreate(AggregateDataPtr place)constoverride { new (place) Data; }
然后调用 agg func add的实现
1 2 3 4 5 6 7 8 9 10
/// Add values to the aggregate functions. for (size_t i = 0; i < aggregate_functions.size(); ++i) { AggregateFunctionInstruction * inst = aggregate_instructions + i;
/** Aggregates the stream of blocks using the specified key columns and aggregate functions. * Columns with aggregate functions adds to the end of the block. * If final = false, the aggregate functions are not finalized, that is, they are not replaced by their value, but contain an intermediate state of calculations. * This is necessary so that aggregation can continue (for example, by combining streams of partially aggregated data). * * For every separate stream of data separate AggregatingTransform is created. * Every AggregatingTransform reads data from the first port till is is not run out, or max_rows_to_group_by reached. * When the last AggregatingTransform finish reading, the result of aggregation is needed to be merged together. * This task is performed by ConvertingAggregatedToChunksTransform. * Last AggregatingTransform expands pipeline and adds second input port, which reads from ConvertingAggregated. * * Aggregation data is passed by ManyAggregatedData structure, which is shared between all aggregating transforms. * At aggregation step, every transform uses it's own AggregatedDataVariants structure. * At merging step, all structures pass to ConvertingAggregatedToChunksTransform. */
AggregatingTransform::work/prepare
见上面章节, 不在赘述, 我们主要看看 work 里的两个方法 consume/initGenerate
boolAggregator::executeOnBlock(Columns columns, UInt64 num_rows, AggregatedDataVariants & result, ColumnRawPtrs & key_columns, AggregateColumns & aggregate_columns, bool & no_more_keys)const { /// `result` will destroy the states of aggregate functions in the destructor result.aggregator = this; ... /// We select one of the aggregation methods and call it. /// For the case when there are no keys (all aggregate into one row). if (result.type == AggregatedDataVariants::Type::without_key) { executeWithoutKeyImpl(result.without_key, num_rows, aggregate_functions_instructions.data(), result.aggregates_pool); } else { /// This is where data is written that does not fit in `max_rows_to_group_by` with `group_by_overflow_mode = any`. AggregateDataPtr overflow_row_ptr = params.overflow_row ? result.without_key : nullptr;
/** Converting to a two-level data structure. * It allows you to make, in the subsequent, an effective merge - either economical from memory or parallel. */ if (result.isConvertibleToTwoLevel() && worth_convert_to_two_level) result.convertToTwoLevel(); ... /** Flush data to disk if too much RAM is consumed. * Data can only be flushed to disk if a two-level aggregation structure is used. */ if (params.max_bytes_before_external_group_by && result.isTwoLevel() && current_memory_usage > static_cast<Int64>(params.max_bytes_before_external_group_by) && worth_convert_to_two_level) { size_t size = current_memory_usage + params.min_free_disk_space;
// enoughSpaceInDirectory() is not enough to make it right, since // another process (or another thread of aggregator) can consume all // space. // // But true reservation (IVolume::reserve()) cannot be used here since // current_memory_usage does not takes compression into account and // will reserve way more that actually will be used. // // Hence let's do a simple check. if (!enoughSpaceInDirectory(tmp_path, size)) throwException("Not enough space for external aggregation in " + tmp_path, ErrorCodes::NOT_ENOUGH_SPACE);
/// Process one data block, aggregate the data into a hash table. voidexecuteImplBatch( Method & method, typename Method::State & state, Arena * aggregates_pool, size_t rows, AggregateFunctionInstruction * aggregate_instructions, AggregateDataPtr overflow_row)const { /// Optimization for special case when there are no aggregate functions. if (params.aggregates_size == 0) { ifconstexpr(no_more_keys) return;
/// For all rows. AggregateDataPtr place = aggregates_pool->alloc(0); for (size_t i = 0; i < rows; ++i) state.emplaceKey(method.data, i, *aggregates_pool).setMapped(place); return; } ... std::unique_ptr<AggregateDataPtr[]> places(new AggregateDataPtr[rows]);
/// For all rows. for (size_t i = 0; i < rows; ++i) { AggregateDataPtr aggregate_data = nullptr;
ifconstexpr(!no_more_keys) { auto emplace_result = state.emplaceKey(method.data, i, *aggregates_pool);
/// If a new key is inserted, initialize the states of the aggregate functions, and possibly something related to the key. if (emplace_result.isInserted()) { /// exception-safety - if you can not allocate memory or create states, then destructors will not be called. emplace_result.setMapped(nullptr);
assert(aggregate_data != nullptr); } else { /// Add only if the key already exists. auto find_result = state.findKey(method.data, i, *aggregates_pool); if (find_result.isFound()) aggregate_data = find_result.getMapped(); else aggregate_data = overflow_row; }
places[i] = aggregate_data; }
/// Add values to the aggregate functions. for (size_t i = 0; i < aggregate_functions.size(); ++i) { AggregateFunctionInstruction * inst = aggregate_instructions + i;
/// To use one `Method` in different threads, use different `State`. using State = ColumnsHashing::HashMethodOneNumber<typename Data::value_type, Mapped, FieldType, consecutive_keys_optimization>;
AggregatedDataVariants
这里可以说整个 agg 的精髓了
这里 CH 给每种数据类型都定义了相应的数据结构, 用来计算的时候更加高效, 每种数据类型都有他自己的类型以及 two_level 的定义, two level 的实现之后会详细介绍
/** Different data structures that can be used for aggregation * For efficiency, the aggregation data itself is put into the pool. * Data and pool ownership (states of aggregate functions) * is acquired later - in `convertToBlocks` function, by the ColumnAggregateFunction object. * * Most data structures exist in two versions: normal and two-level (TwoLevel). * A two-level hash table works a little slower with a small number of different keys, * but with a large number of different keys scales better, because it allows * parallelize some operations (merging, post-processing) in a natural way. * * To ensure efficient work over a wide range of conditions, * first single-level hash tables are used, * and when the number of different keys is large enough, * they are converted to two-level ones. * * PS. There are many different approaches to the effective implementation of parallel and distributed aggregation, * best suited for different cases, and this approach is just one of them, chosen for a combination of reasons. */
/// For the case where there is one numeric key. /// FieldType is UInt8/16/32/64 for any type with corresponding bit width. template <typename FieldType, typename TData, bool consecutive_keys_optimization = true> struct AggregationMethodOneNumber { using Data = TData; using Key = typename Data::key_type; using Mapped = typename Data::mapped_type;
Data data;
AggregationMethodOneNumber() = default;
template <typename Other> AggregationMethodOneNumber(const Other & other) : data(other.data) {}
/// To use one `Method` in different threads, use different `State`. using State = ColumnsHashing::HashMethodOneNumber<typename Data::value_type, Mapped, FieldType, consecutive_keys_optimization>;
/// Use optimization for low cardinality. staticconstbool low_cardinality_optimization = false;
/// Shuffle key columns before `insertKeyIntoColumns` call if needed. std::optional<Sizes> shuffleKeyColumns(std::vector<IColumn *> &, const Sizes &){ return {}; }
// Insert the key from the hash table into columns. staticvoidinsertKeyIntoColumns(const Key & key, std::vector<IColumn *> & key_columns, const Sizes & /*key_sizes*/) { constauto * key_holder = reinterpret_cast<constchar *>(&key); auto * column = static_cast<ColumnVectorHelper *>(key_columns[0]); column->insertRawData<sizeof(FieldType)>(key_holder); } };
/** Used as a lookup table for small keys such as UInt8, UInt16. It's different * than a HashTable in that keys are not stored in the Cell buf, but inferred * inside each iterator. There are a bunch of to make it faster than using * HashTable: a) It doesn't have a conflict chain; b) There is no key * comparison; c) The number of cycles for checking cell empty is halved; d) * Memory layout is tighter, especially the Clearable variants. * * NOTE: For Set variants this should always be better. For Map variants * however, as we need to assemble the real cell inside each iterator, there * might be some cases we fall short. **/
FixedHashTable/TwoLevelHashTable
记个 todo 把 看不动
AggregatedDataWithUInt64KeyTwoLevel
using AggregatedDataWithUInt64KeyTwoLevel = TwoLevelHashMap<UInt64, AggregateDataPtr, HashCRC32<UInt64>>;
/** Working with states of aggregate functions in the pool is arranged in the following (inconvenient) way: * - when aggregating, states are created in the pool using IAggregateFunction::create (inside - `placement new` of arbitrary structure); * - they must then be destroyed using IAggregateFunction::destroy (inside - calling the destructor of arbitrary structure); * - if aggregation is complete, then, in the Aggregator::convertToBlocks function, pointers to the states of aggregate functions * are written to ColumnAggregateFunction; ColumnAggregateFunction "acquires ownership" of them, that is - calls `destroy` in its destructor. * - if during the aggregation, before call to Aggregator::convertToBlocks, an exception was thrown, * then the states of aggregate functions must still be destroyed, * otherwise, for complex states (eg, AggregateFunctionUniq), there will be memory leaks; * - in this case, to destroy states, the destructor calls Aggregator::destroyAggregateStates method, * but only if the variable aggregator (see below) is not nullptr; * - that is, until you transfer ownership of the aggregate function states in the ColumnAggregateFunction, set the variable `aggregator`, * so that when an exception occurs, the states are correctly destroyed. * * PS. This can be corrected by making a pool that knows about which states of aggregate functions and in which order are put in it, and knows how to destroy them. * But this can hardly be done simply because it is planned to put variable-length strings into the same pool. * In this case, the pool will not be able to know with what offsets objects are stored. */
size_t keys_size{}; /// Number of keys. NOTE do we need this field? Sizes key_sizes; /// Dimensions of keys, if keys of fixed length
/// Pools for states of aggregate functions. Ownership will be later transferred to ColumnAggregateFunction. Arenas aggregates_pools; Arena * aggregates_pool{}; /// The pool that is currently used for allocation.
// Disable consecutive key optimization for Uint8/16, because they use a FixedHashMap // and the lookup there is almost free, so we don't need to cache the last lookup result std::unique_ptr<AggregationMethodOneNumber<UInt8, AggregatedDataWithUInt8Key, false>> key8; std::unique_ptr<AggregationMethodOneNumber<UInt16, AggregatedDataWithUInt16Key, false>> key16;
/** Memory pool to append something. For example, short strings. * Usage scenario: * - put lot of strings inside pool, keep their addresses; * - addresses remain valid during lifetime of pool; * - at destruction of pool, all memory is freed; * - memory is allocated and freed by large MemoryChunks; * - freeing parts of data is not possible (but look at ArenaWithFreeLists if you need); */
1 2 3 4 5 6 7 8 9 10
/** * ArenaKeyHolder is a key holder for hash tables that serializes a StringRef * key to an Arena. */ structArenaKeyHolder { StringRef key; Arena & pool;
};
AggregatingTransform::initGenerate
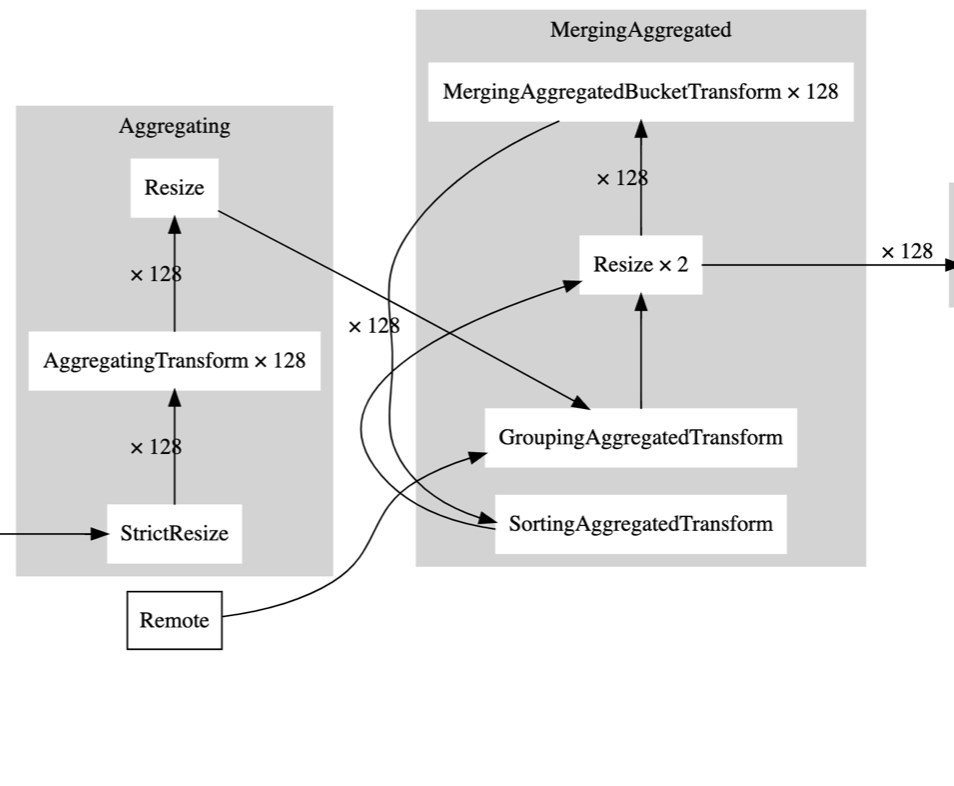
ConvertingAggregatedToChunksTransform
1 2 3 4 5 6 7 8 9
/// Generates chunks with aggregated data. /// In single level case, aggregates data itself. /// In two-level case, creates `ConvertingAggregatedToChunksSource` workers: /// /// ConvertingAggregatedToChunksSource -> /// ConvertingAggregatedToChunksSource -> ConvertingAggregatedToChunksTransform -> AggregatingTransform /// ConvertingAggregatedToChunksSource -> /// /// Result chunks guaranteed to be sorted by bucket number.
voidcreateSources() { AggregatedDataVariantsPtr & first = data->at(0); shared_data = std::make_shared<ConvertingAggregatedToChunksSource::SharedData>();
for (size_t thread = 0; thread < num_threads; ++thread) { /// Select Arena to avoid race conditions Arena * arena = first->aggregates_pools.at(thread).get(); auto source = std::make_shared<ConvertingAggregatedToChunksSource>(params, data, shared_data, arena);
processors.emplace_back(std::move(source)); } }
MergingAggregatedTransform
MergingAggregatedTransform::consume
如果是 two level 的, 则可以并行
1 2 3 4 5 6 7 8 9 10 11
/** If the remote servers used a two-level aggregation method, * then blocks will contain information about the number of the bucket. * Then the calculations can be parallelized by buckets. * We decompose the blocks to the bucket numbers indicated in them. */
auto block = getInputPort().getHeader().cloneWithColumns(chunk.getColumns()); block.info.is_overflows = agg_info->is_overflows; block.info.bucket_num = agg_info->bucket_num;
/// TODO: this operation can be made async. Add async for IAccumulatingTransform. params->aggregator.mergeBlocks(std::move(bucket_to_blocks), data_variants, max_threads); blocks = params->aggregator.convertToBlocks(data_variants, params->final, max_threads); next_block = blocks.begin();
官网: When merging data flushed to the disk, as well as when merging results from remote servers when the distributed_aggregation_memory_efficient setting is enabled, consumes up to 1/256 * the_number_of_threads from the total amount of RAM.
/// Read first time from each input to understand if we have two-level aggregation. if (!read_from_all_inputs) { readFromAllInputs(); if (!read_from_all_inputs) return Status::NeedData; }
/// Convert single level to two levels if have two-level input. if (has_two_level && !single_level_chunks.empty()) return Status::Ready;
/// Check can push (to avoid data caching). if (!output.canPush()) { for (auto & input : inputs) input.setNotNeeded();
return Status::PortFull; }
bool pushed_to_output = false;
/// Output if has data. if (has_two_level) pushed_to_output = tryPushTwoLevelData();
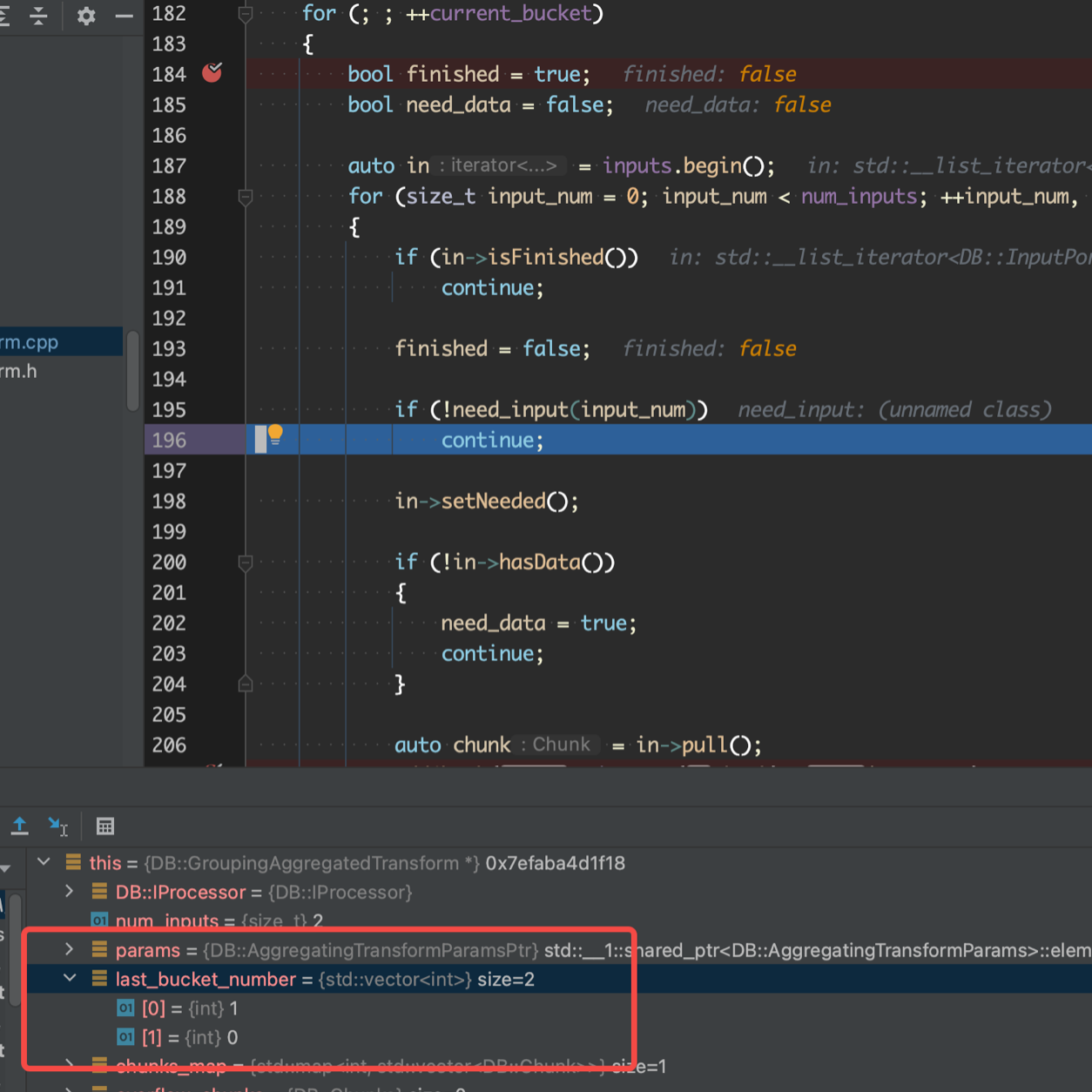
auto need_input = [this](size_t input_num) { if (last_bucket_number[input_num] < current_bucket) returntrue;
/// Read next bucket if can. for (; ; ++current_bucket) { bool finished = true; bool need_data = false;
auto in = inputs.begin(); for (size_t input_num = 0; input_num < num_inputs; ++input_num, ++in) { if (in->isFinished()) continue;
finished = false;
if (!need_input(input_num)) continue;
in->setNeeded();
if (!in->hasData()) { need_data = true; continue; }
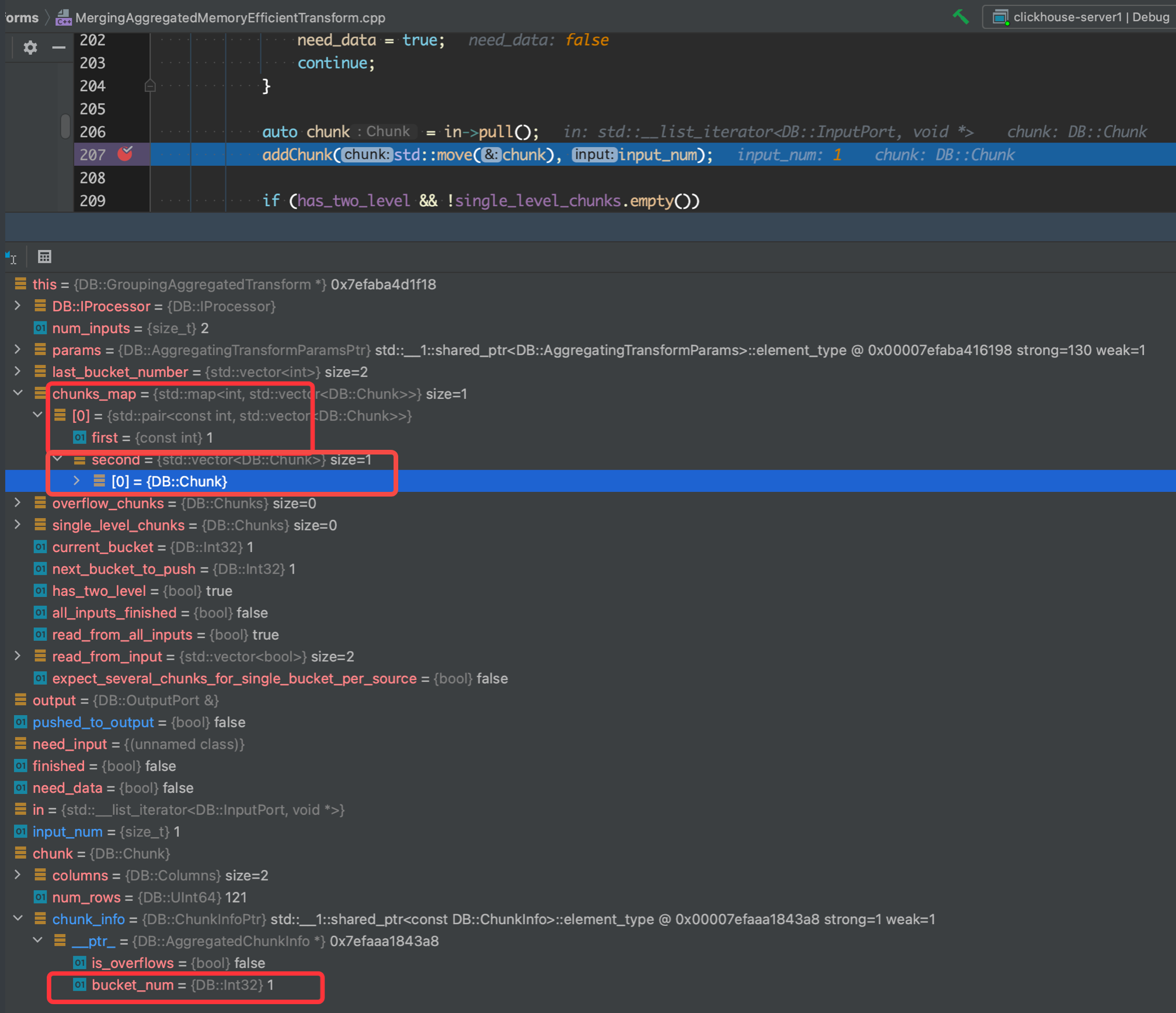
auto chunk = in->pull(); addChunk(std::move(chunk), input_num);
if (has_two_level && !single_level_chunks.empty()) return Status::Ready;
if (!in->isFinished() && need_input(input_num)) need_data = true; }
if (finished) { all_inputs_finished = true; break; }
if (need_data) return Status::NeedData; }
if (pushed_to_output) return Status::PortFull;
if (has_two_level) { if (tryPushTwoLevelData()) return Status::PortFull;
/// Sanity check. If new bucket was read, we should be able to push it. /// This is always false, but we still keep this condition in case the code will be changed. if (!all_inputs_finished) // -V547 throwException("GroupingAggregatedTransform has read new two-level bucket, but couldn't push it.", ErrorCodes::LOGICAL_ERROR); } else { if (!all_inputs_finished) // -V547 throwException("GroupingAggregatedTransform should have read all chunks for single level aggregation, " "but not all of the inputs are finished.", ErrorCodes::LOGICAL_ERROR);
if (tryPushSingleLevelData()) return Status::PortFull; }
/// If we haven't pushed to output, then all data was read. Push overflows if have. if (tryPushOverflowData()) return Status::PortFull;
output.finish(); return Status::Finished; }
比较关键的是里面两个 for 循环, 会遍历所有的 inputs, 如果 input 的当前的 last_bucket_number(Last bucket read from each input) 小于 current_bucket(``need_input` 方法), 就说明需要从上游 pull data
voidGroupingAggregatedTransform::addChunk(Chunk chunk, size_t input) { constauto & info = chunk.getChunkInfo(); if (!info) throwException("Chunk info was not set for chunk in GroupingAggregatedTransform.", ErrorCodes::LOGICAL_ERROR);
constauto * agg_info = typeid_cast<const AggregatedChunkInfo *>(info.get()); if (!agg_info) throwException("Chunk should have AggregatedChunkInfo in GroupingAggregatedTransform.", ErrorCodes::LOGICAL_ERROR);
if (all_inputs_finished) { /// Chunks are sorted by bucket. while (!chunks_map.empty()) if (try_push_by_iter(chunks_map.begin())) returntrue; } else { for (; next_bucket_to_push < current_bucket; ++next_bucket_to_push) if (try_push_by_iter(chunks_map.find(next_bucket_to_push))) returntrue; }
if (!chunks_to_merge) throwException("MergingAggregatedSimpleTransform chunk must have ChunkInfo with type ChunksToMerge.", ErrorCodes::LOGICAL_ERROR);
auto header = params->aggregator.getHeader(false);
BlocksList blocks_list; for (auto & cur_chunk : *chunks_to_merge->chunks) { constauto & cur_info = cur_chunk.getChunkInfo(); if (!cur_info) throwException("Chunk info was not set for chunk in MergingAggregatedBucketTransform.", ErrorCodes::LOGICAL_ERROR);
constauto * agg_info = typeid_cast<const AggregatedChunkInfo *>(cur_info.get()); if (!agg_info) throwException("Chunk should have AggregatedChunkInfo in MergingAggregatedBucketTransform.", ErrorCodes::LOGICAL_ERROR);